前言
本文主要说明缓冲区溢出及其发生方式。缓冲区溢出是通过覆盖进程或程序的内存片段而发生的。覆盖进程的某些指针和寄存器的值会导致分段错误,从而导致多个错误,从而导致以异常方式终止程序执行。
缓冲区溢出的定义
缓冲区是一种易丢失的内存配置,它们当数据从一个位置转移到另一个位置时临时性的保存这些数据。当正在处理的数据超过内存缓冲区的存储容量时,会发生缓冲区溢出。项目中这种结果会造成溢出数据覆盖到相邻内存位置,从而导致缓冲区溢出。当我们对 char 类型的缓冲区进行操作时,会发生缓冲区溢出。
我们将尝试用几个例子来理解这个概念。例如,一个缓冲区设定为只能接受8字节的数据,在这种情况下,如果用户输入的数据超过8字节,则超过8字节的数据部分将覆盖相邻内存从而超过已分配缓冲区的边界。这最终会产生分段错误,之后引发许多其他错误,导致程序执行被终止。
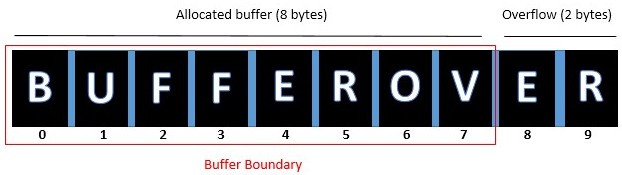
如上所述,分配的内存是8个字节,而用户输入的数据是10个字节,超过了缓冲区边界,而那些额外的2个字节的数据(E&R)覆盖了相邻的内存位置。现在我们已经大致了解了缓冲区溢出,是时候对缓冲区溢出的类型进行一些了解了。
缓冲区溢出类型
缓冲区溢出有两种类型,一种是栈缓冲区溢出,一种是堆缓冲区溢出。我们来对其总结一下。
栈缓冲区溢出
当一个程序覆盖到一个内存地址,但该地址在一个固定长度的程序所调用缓冲区边界以外的位置,就会发生这种情况。在栈缓冲区溢出中,额外的数据被写入堆栈上的相邻缓冲区中。这通常会导致应用程序崩溃,因为这种堆栈上溢出会导致内存损坏方面的错误。
堆缓冲区溢出
堆是一种用于动态内存分配管理的内存结构。它通常用于分配在编译时大小未知的内存,其中所需的内存量太大以至于无法安装在堆栈上。堆溢出或堆喷是堆数据区域中发生的一种缓冲区溢出。基于堆的溢出的利用不同于基于栈的溢出利用。堆上的内存是在运行时动态分配的且通常包含程序数据。利用堆缓冲区溢出漏洞是通过以特定方式损坏此数据来完成的,从而导致应用程序覆盖内部结构(例如链表指针)。
缓冲区溢出攻击
最常见的缓冲区溢出攻击称为基于堆栈的缓冲区溢出或普通缓冲区溢出攻击,该堆栈通常为空,直到程序需要用户输入(如用户名或密码)。否则该堆栈通常为空。然后,程序将返回内存地址写入堆栈,然后将用户的输入存储在堆栈之上。在处理堆栈时,用户的输入将发送到程序指定的返回地址。
但是,堆栈的特定内存量在开始时分配,这使得它有限。如果用户输入的数据大于堆栈中分配的内存量,并且程序没有任何输入验证,可以验证提供的数据是否适合分配的内存,则将导致溢出。
如果堆栈缓冲区中充满了不受信任的用户提供的数据,则用户可以以将恶意可执行代码注入正在运行的程序并控制进程的方式损坏堆栈。
栈缓冲区溢出原理
借助示例可以理解基于堆栈的缓冲区溢出事件。我们将使用一个非常简单的C++程序来演示基于堆栈的缓冲区溢出。
#include <iostream>
using namespace std;
int main()
{
char buffer[8];
cout<<“Input data : ";
cin>>buffer;
return 0;
}
在上面的代码中,我们使用了一个字符型变量,并创建了一个名为"buffer"的数组,该数组最多可以存储8个字节的数据。此程序在执行时等待用户输入。用户将数据放入输入字段后,应用程序会将值存储在分配的 8 个字节的内存中。如果用户提供的数据大于 8 个字节,则会覆盖相邻的内存位置,从而导致进程终止。
您可以使用任何C++编译器来执行上述给定的程序。为此,我们使用了一个在线编译器。只需将上述源代码复制粘贴到编译器中,然后点击运行按钮即可。

编译后,程序被执行。在第一次执行时,我们提供了"bufferov"作为输入数据。
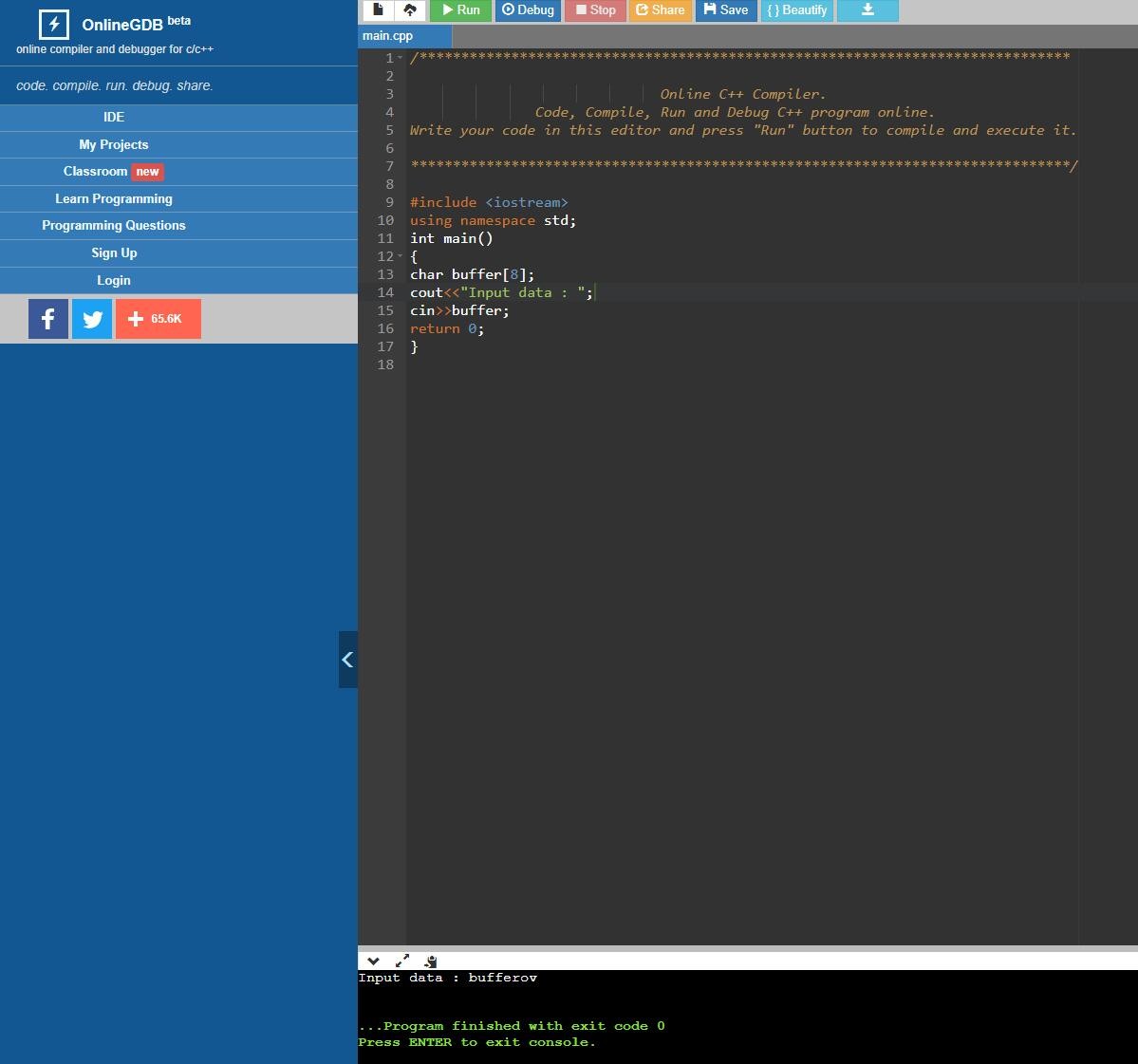
正如我们在上图中看到的那样,程序正常退出,退出代码为0。退出代码 0 表示进程的成功执行。这是因为用户提供的数据输入仅为 8 个字节。
随后,我们通过在输入字段中提供"bufferoverflow"作为输入数据来测试程序,并检查了结果。
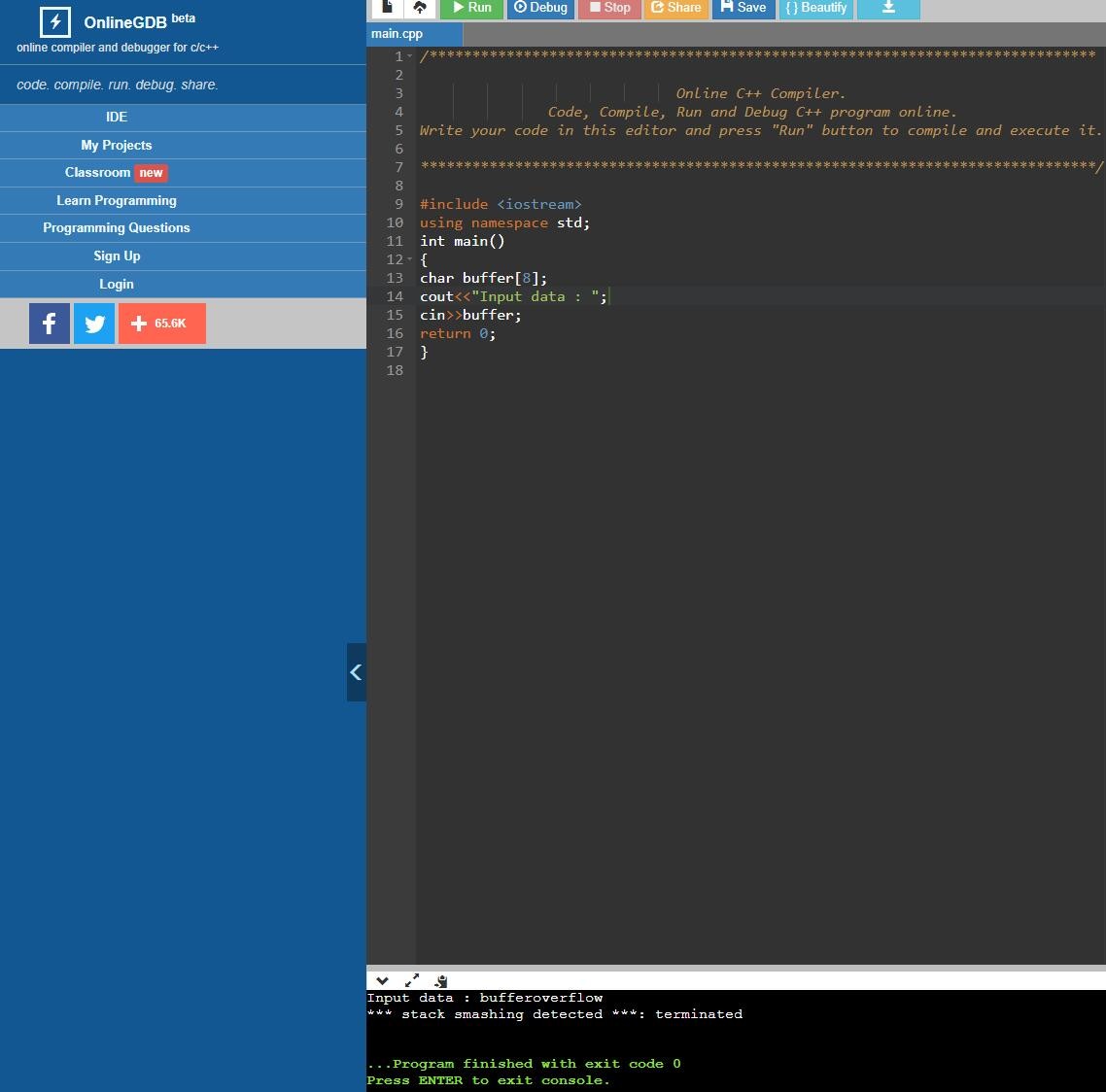
正如我们在上图中看到的,它说检测到堆栈粉碎,并且程序退出,退出代码为134。退出代码 134 表示程序已中止(收到 SIGABRT),这可能是由于断言失败的结果。
检测到的堆栈粉碎错误是由编译器生成的,以响应其针对缓冲区溢出的防御机制。此处发生缓冲区溢出,因为分配的缓冲区设计为仅保存 8 个字节,而用户提供的输入数据为 14 个字节。这额外的 6 个字节超过了缓冲区边界,覆盖了堆栈中存在的相邻内存位置。这创建了分段错误,导致堆栈粉碎错误。
结束语
本文主要说明了栈缓冲区溢出和堆缓冲区溢出攻击的基本概念。
并且通过具体的程序演示说明了缓冲区溢出的原理。