零基础利用chatgpt进行编程
1.chatgpt简介
根据最新数据, ChatGPT日活跃用户数的增速远超Instagram。截至2023年3月,平均每天有超过1500万名独立访问者使用ChatGPT,相较于去年12月份增长了超过两倍。国内外科技巨头都非常重视ChatGPT引发的科技浪潮,积极布局生成式AI,国内厂商(如百度、腾讯等)也在高度关注ChatGPT,积极探索前沿技术,相关深度应用也即将推出。
ChatGPT所依赖的多种技术模型积累来自机器学习、神经网络以及Transformer模型等领域的不断演化。随着Transformer建模方法的成熟,开发各种模态的基础模型并利用一套统一的工具得以实现。GPT-1、GPT-2和GPT-3模型的持续演化和升级最终孵化出ChatGPT文本对话应用。目前,AIGC产业生态在文本、音频、视频等多模态交互功能上持续演化升级,并奠定了多场景的商用基础。跨模态生成技术有望成为真正实现认知和决策智能的转折点。随着ChatGPT Plus发布,商业化序幕已经拉开。
ChatGPT在传媒、影视、营销、娱乐以及数实共生均有着广泛应用场景,是产业升级和生产力曲线提升的强大助力。同时还能够多维度赋能虚拟经济和实体经济。
除了日活跃用户数增长迅速,ChatGPT在使用体验方面也持续得到用户的高度认可。其自然语言处理能力不断提高,更加准确地理解人类语言意图,提供个性化、实时、有效的交互服务。ChatGPT在智能客服、智能问答、情感分析、推荐引擎等多个领域有着广泛应用,并且已经开始探索更多领域的应用场景,如医疗、金融、教育等。
同时,ChatGPT Plus的发布标志着商业化进程的启动,未来可以预见ChatGPT将会呈现更加多元化的形态和更广泛的应用场景。作为AIGC产业的重要组成部分,ChatGPT在文本、音频、视频等多模态交互功能上持续发力,并且还将通过跨模态生成技术实现认知和决策智能的重大突破。
总之,ChatGPT在技术、用户、商业应用等方面呈现出快速发展的趋势,将为全球各行各业带来更加智能化的体验和更高效的产业升级。
1.1chatgpt前世今生
ChatGPT(Generative Pretrained Transformer)是一种基于Transformer模型的自然语言处理技术,是目前最先进的对话生成模型之一。它由OpenAI实验室开发,利用了大规模的无标注数据来进行预训练,从而能够针对不同的对话任务进行微调。
ChatGPT的优势在于其强大的语言生成能力和上下文感知能力。它可以根据历史对话内容生成连贯、自然的回复,并且能够理解和维护上下文信息,从而生成更加智能、准确的回复。由于其强大的泛化能力,ChatGPT已被广泛应用于多个领域,例如客服机器人、智能问答等。
目前,ChatGPT已经更新到第4代(GPT-4),其模型规模和性能将会更加强大,有望推动对话生成技术的发展。
1.2ChatGpt主要功能
ChatGPT的主要功能之一是针对自然语言处理任务进行微调,例如问答系统、客服机器人等。通过将模型微调到特定任务,可以提高ChatGPT在该任务上的性能和准确度。此外,ChatGPT还可以用于生成各种类型的自然语言文本,例如电子邮件、新闻文章、故事等。这些生成的文本可以用于多种应用,例如自动化写作、自动翻译和情感分析等。总而言之,ChatGPT的主要功能是使用其强大的自然语言理解和生成能力来实现多样化的自然语言处理任务。
1.3ChatGpt具体应用领域和落地场景
客户服务领域: ChatGpt在客户服务领域有着广泛应用,可以为大型企业提供智能客服解决方案,实现快速响应、高效处理、自动化回答等服务,提升客户服务质量和效率。
智能问答领域: ChatGpt可以应用于智能问答系统,为用户提供更加全面、精准的问题解答,涉及医疗、法律、金融等多个垂直领域的问答服务。
情感分析领域: ChatGpt可以进行情感识别和情感分析,可以应用于品牌管理、舆情监测、个性化推荐等场景。
推荐引擎领域: ChatGpt可以进行个性化推荐,例如电商平台、社交平台等。
营销领域: ChatGpt可以用于智能广告投放、社交媒体营销等场景。
教育领域: ChatGpt可以用于在线教育场景,例如智能教学助手、自动作文等。
医疗领域: ChatGpt可以应用于医疗领域,如智能问诊、辅助诊断等场景。
1.4ChatGpt使用条件及方法
目前OpenAI API尚未全球开放,中国大陆地区暂不支持,其使用流程如下
(1)创建账户:首先需要去OpenAI官网注册账户,并选择相应的访问级别。目前,OpenAI在官网上提供了一组API密钥,开发者可以使用这些API密钥访问不同的AI功能。
安装OpenAI API:接下来,需要安装OpenAI API,安装完成后,可以使用curl或Python客户端与ChatGPT建立连接,并使用API密钥进行身份验证。
(2)选择模型:OpenAI提供了多种预训练模型可供使用,包括GPT-3、GPT-2等。根据具体需求选择相应的模型。
(3)调用API:使用API密钥与ChatGPT建立连接后,可以通过调用API接口来实现与ChatGPT的交互。具体来说,可以使用curl或Python客户端调用API接口,向ChatGPT提出问题或任务,并接收ChatGPT的回答或结果。
总之,使用ChatGPT需要先创建账户、安装OpenAI API、选择模型,然后通过API接口实现与ChatGPT的交互。此外,还需要注意保护API密钥,避免泄露。
2.寻找可用的chatgpt
Chatgpt目前并不对中国大陆开放,使用者需要翻墙才能访问,不过目前网上有很多技术爱好者搭建了chatgpt平台,通过申请账号,配置好密钥,普通用户也可以直接使用,下面是一些可以接触并使用到chatgpt的方法和路径。
2.1通过资产搜索工具搜索chatgpt
2.1.1使用fofa搜索chatgpt
在fofa.info网站输入"loading-wrap" && "balls" && "chat" && is_domain=true进行搜索,可以获取互联网上提供chatgpt的域名或者IP地址。也可以换关键字“ChatGPT Web”进行搜索。
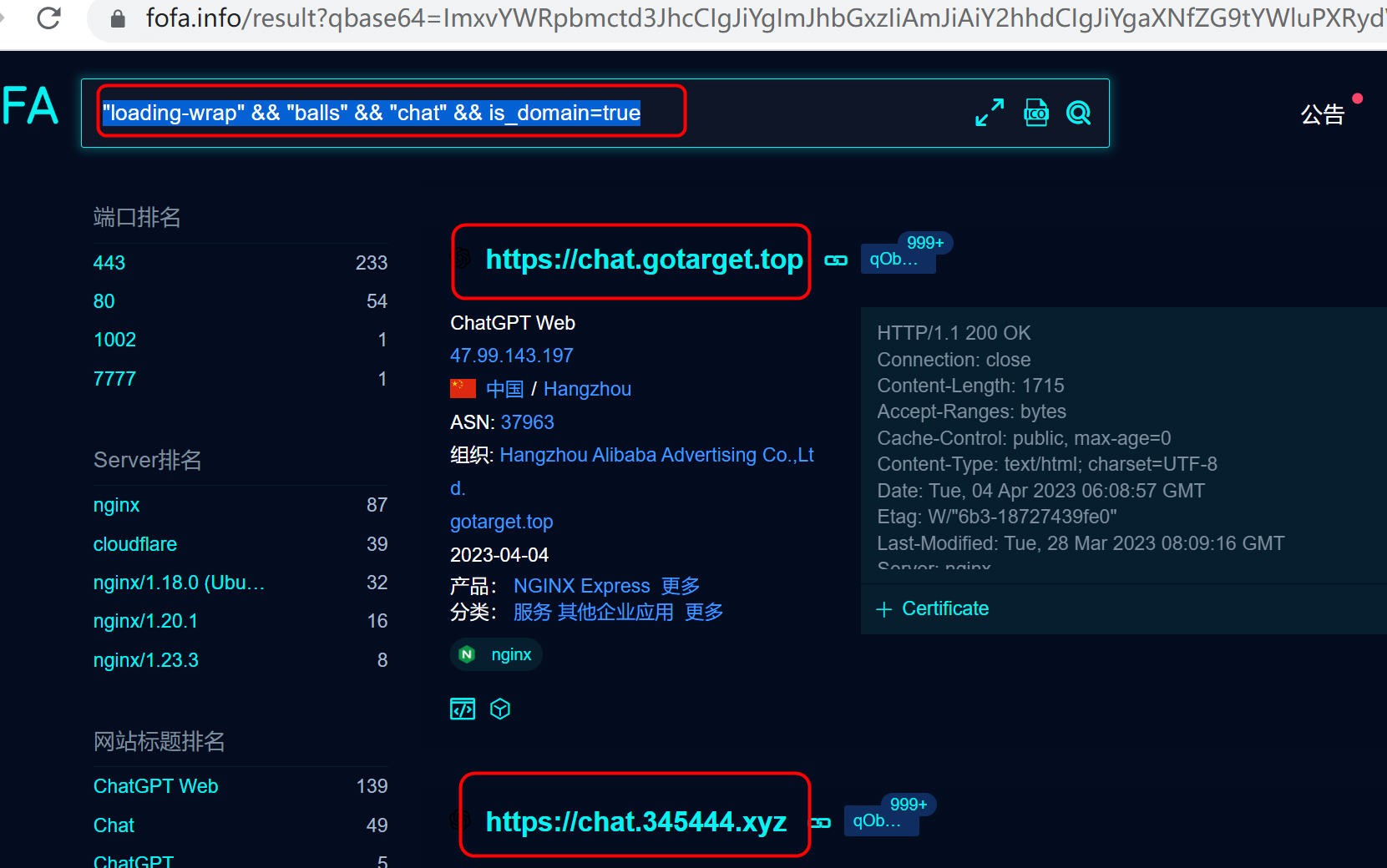
图1 通过fofa搜索chatgpt
2.1.2使用zoomeye进行搜索
在zoomeys中通过命令title:"ChatGPT Web"来搜索提供ChatGPT服务的IP或者网站,有的网站需要输入密码验证才能使用。
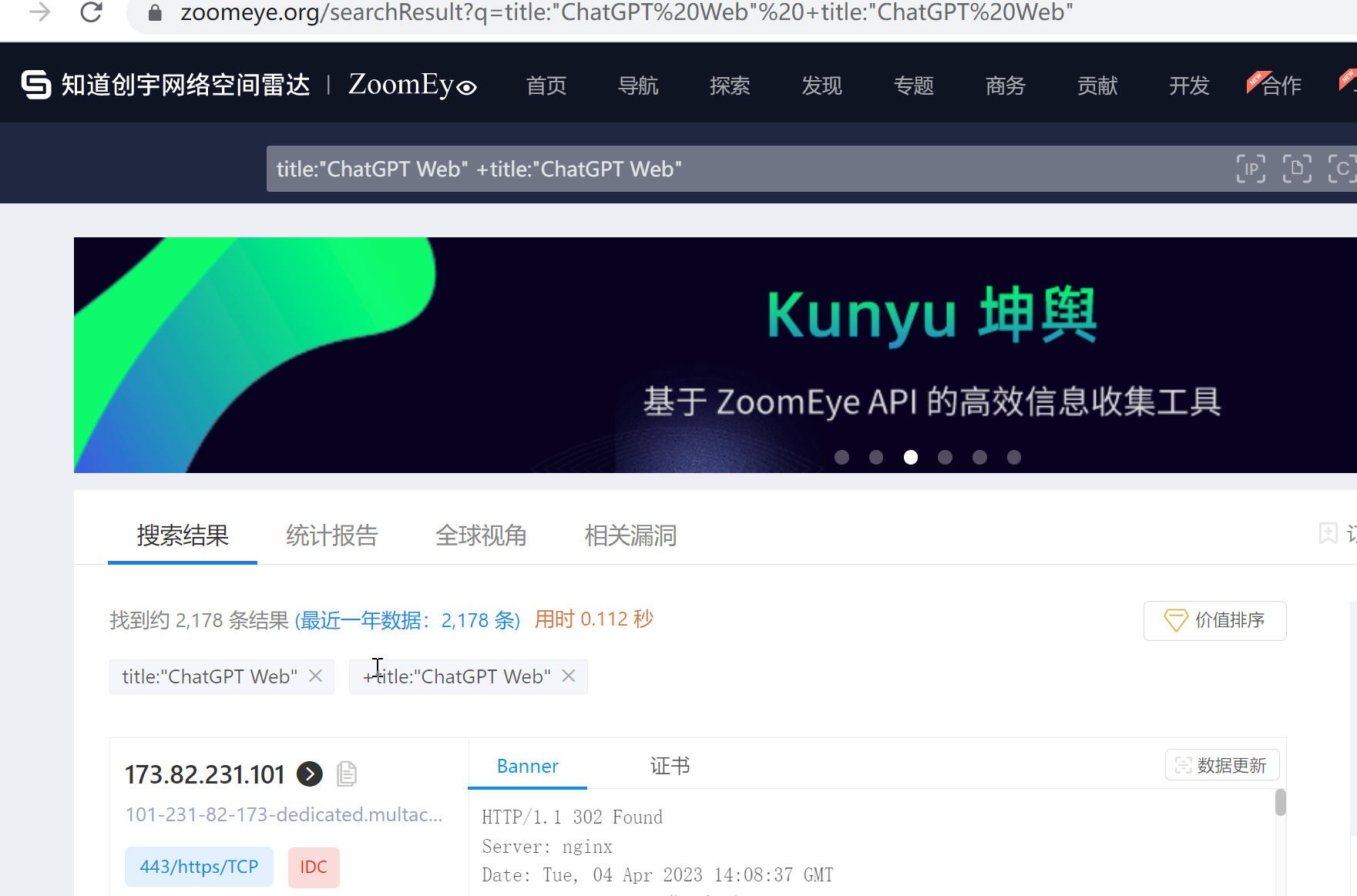
图2 zoomeye搜索chatgpt web
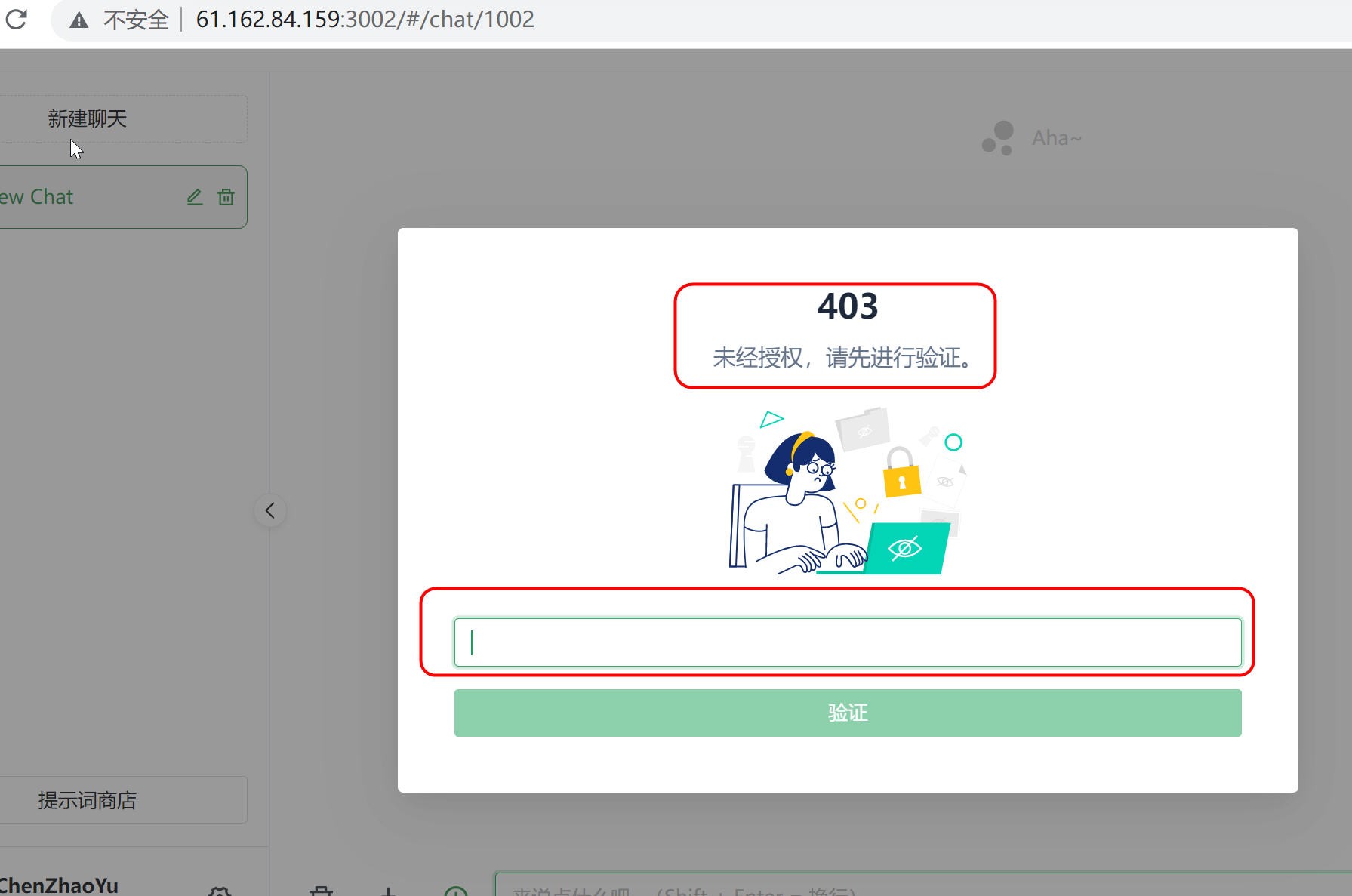
图3 需要授权验证访问
还可以通过搜索图标hash值来获取例如:iconhash:"fc0a454982ec43840713b8db0f58a747"
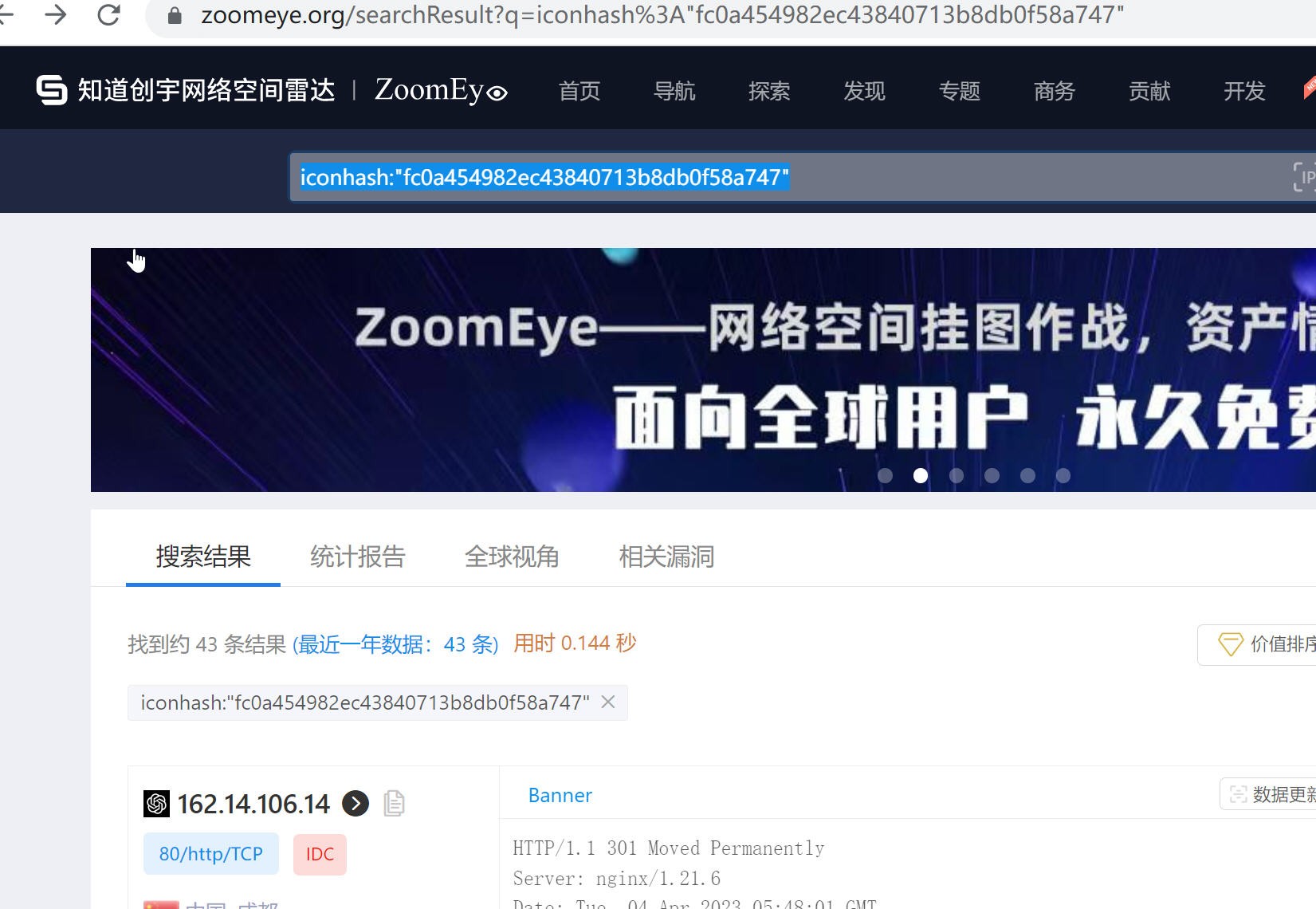
图4 搜索iconhash值来获取
2.1.3自己搭建
自己动手搭建可以参考开源代码:
https://github.com/dirk1983/chatgpt
https://github.com/lianshufeng/chatgpt_api_demo
详细搭建文章可以参考:
https://blog.csdn.net/weixin_47059371/article/details/129789380
3.通过训练chatgpt来进行编程
3.1准备阶段
3.1.1可以实际使用的chatgpt网站
通过上面的步骤首先找到一个可以使用chatgpt网站,通过资产工具搜索可以多查看一些搜索结果,从中找到一些可以不使用密钥登录的如https://chat.jpy.wang/#/chat/1002
3.1.2通过编程来达到什么目的
以前需要熟悉编程语言,有了chatgpt后可以将功能描述清楚,通过训练和实际测试,直接获取一段处理代码,因此你要想清楚到底需要解决什么问题。
3.1.3整理原始需求
例如笔者想解决多个文件的合并问题,这种xlsx文件如果几个文件合并可以手工,当超过上千个文件后就比较麻烦。其原始需求整理如下:
对n个文件进行合并,这些文件格式相同。统一到一个文件方便进行查看和分析。
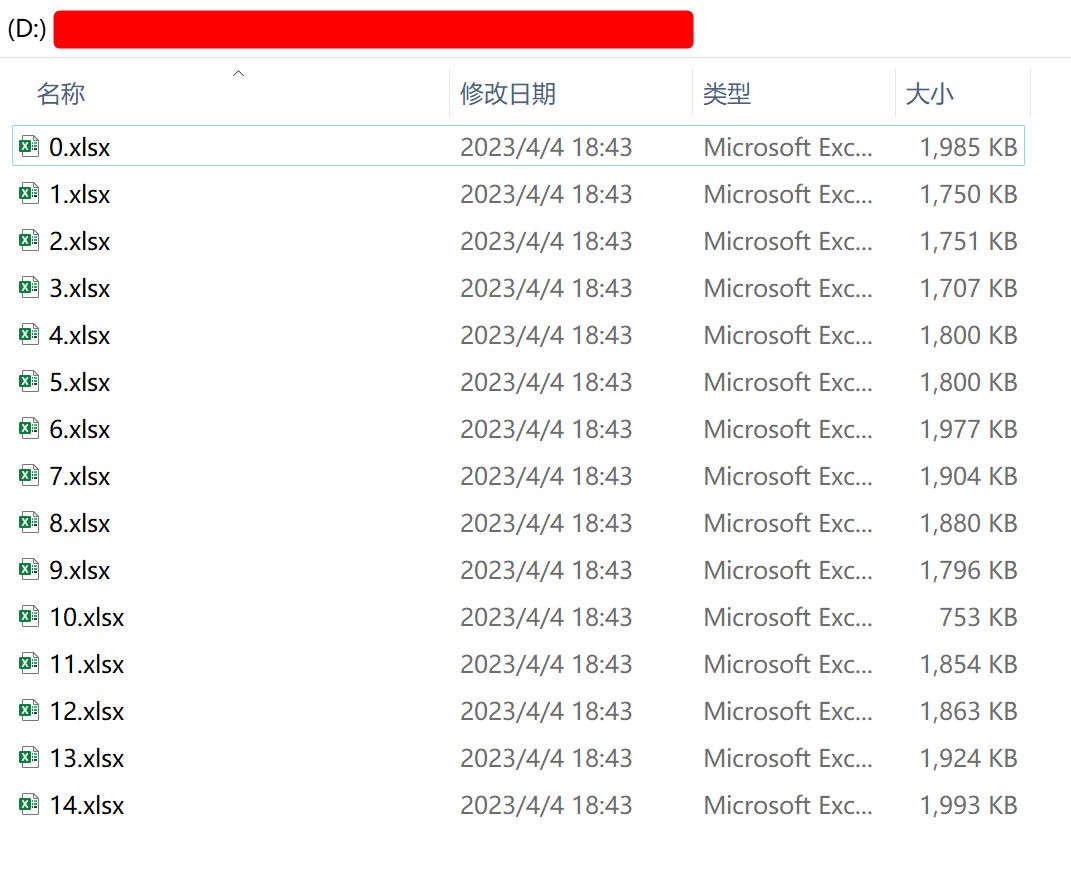
图5 原始需求处理xlsx文件
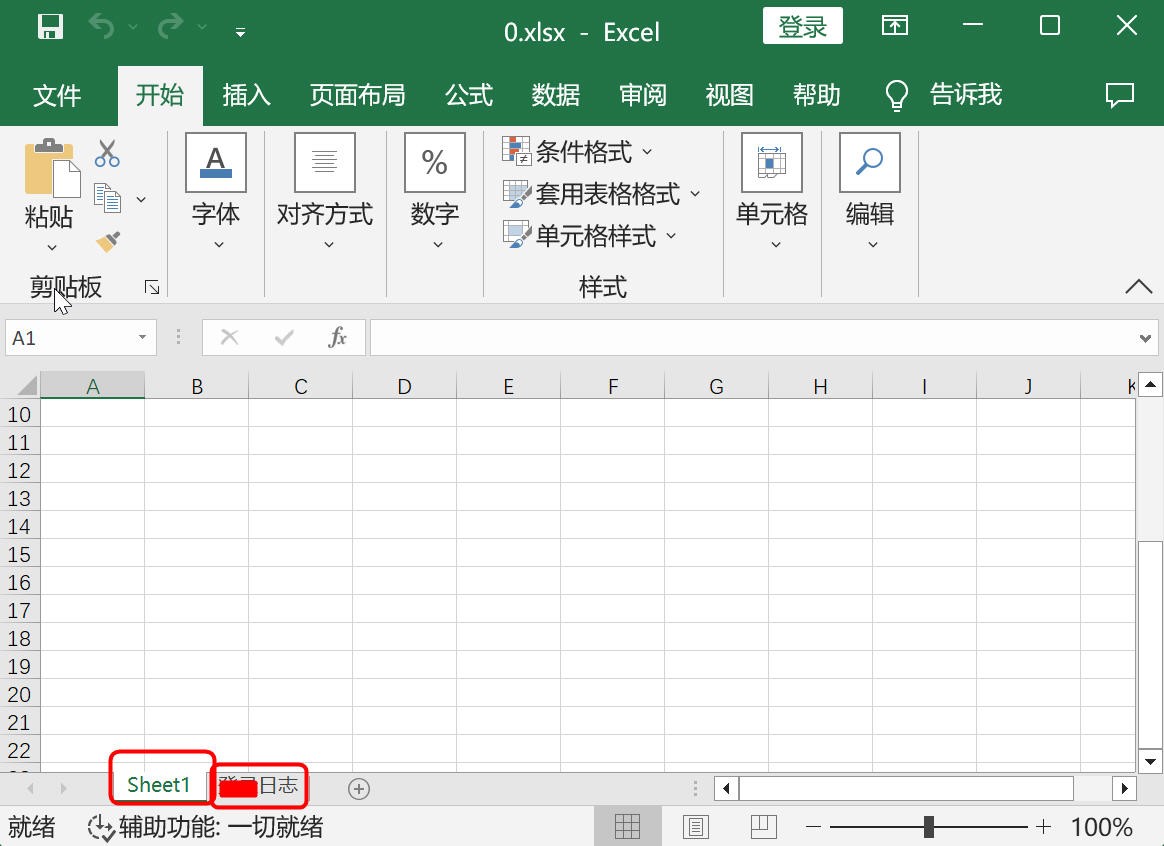
图6 原始文件需要删除sheet空文件
3.1.4详细描述需求
在chatgpt中需要一个明确的输入,这样才能达到效果,例如详细需求如下:
(1)目标对象为xlsx文件,所有文件保存在all目录
(2)所有文件的表格式相同
(3)需要删除表中的一个空表sheet1
(4)将表中的内容进行合并,字段以逗号分开,处理后保存为out.txt文件
根据以上需求请编写一个python程序
3. 5训练模型
3.5.1第一次训练效果
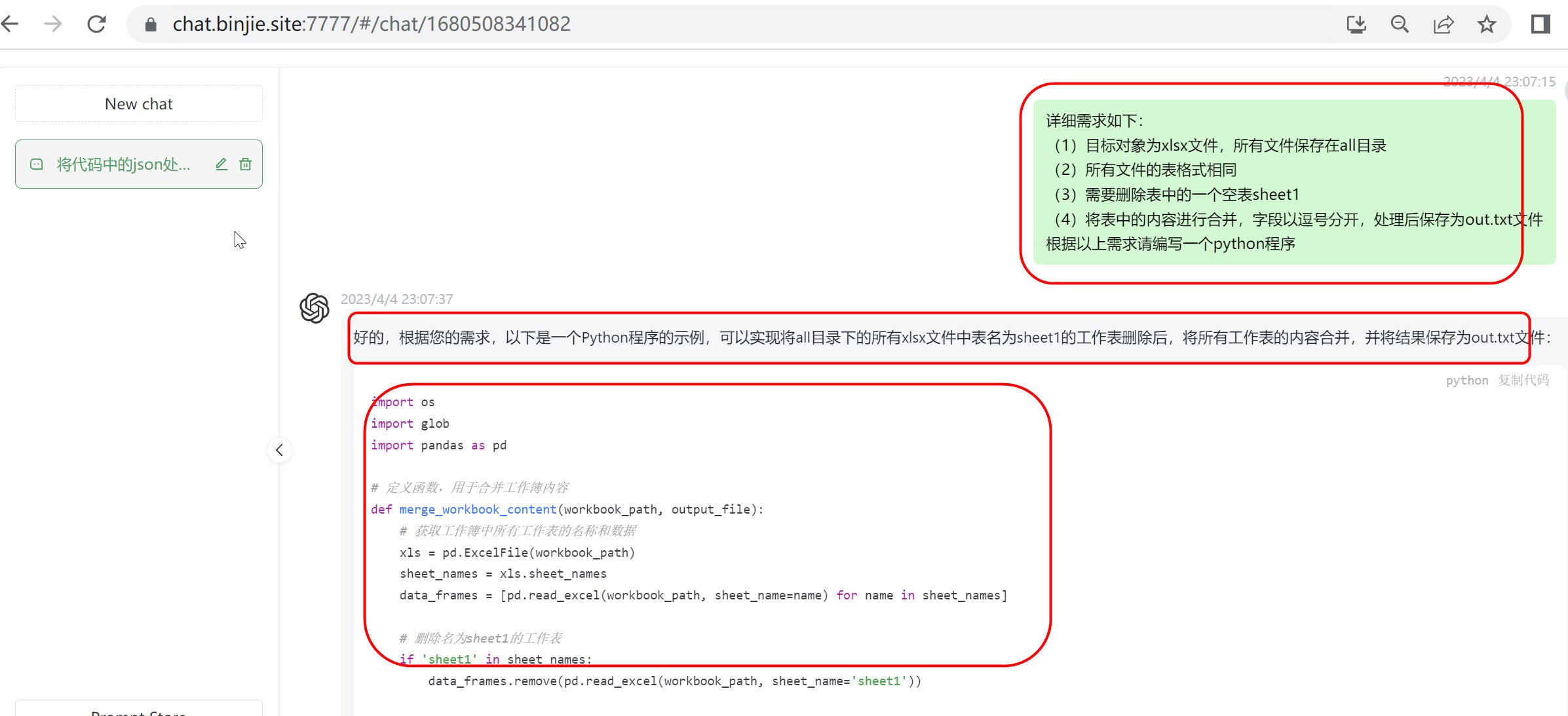
图7 第一次训练
代码如下:
`import os
import openpyxl
指定文件夹路径
folder_path = "./all"
遍历文件夹内的所有xlsx文件
for filename in os.listdir(folder_path):
if filename.endswith(".xlsx"):
打开工作簿
filepath = os.path.join(folder_path, filename)
workbook = openpyxl.load_workbook(filepath)
# 删除表中的空表sheet1
if 'Sheet1' in workbook.sheetnames:
workbook.remove(workbook['Sheet1'])
# 合并表中的内容
worksheet = workbook.active
rows = worksheet.rows
header = [cell.value for cell in next(rows)] # 表头
with open('out.txt', 'a') as f:
for row in rows:
# 将行数据合并为逗号分隔的字符串
row_data = [cell.value for cell in row]
row_str = ','.join(str(cell) if cell else '' for cell in row_data)
# 将表头和行数据拼接为一行
row_text = ','.join(str(cell) for cell in header) + '\n' + row_str + '\n'
f.write(row_text)
`
2.执行测试
(1)先对数据进行备份
(2)执行代码
第一次执行需要安装模块
python -m pip install openpyxl
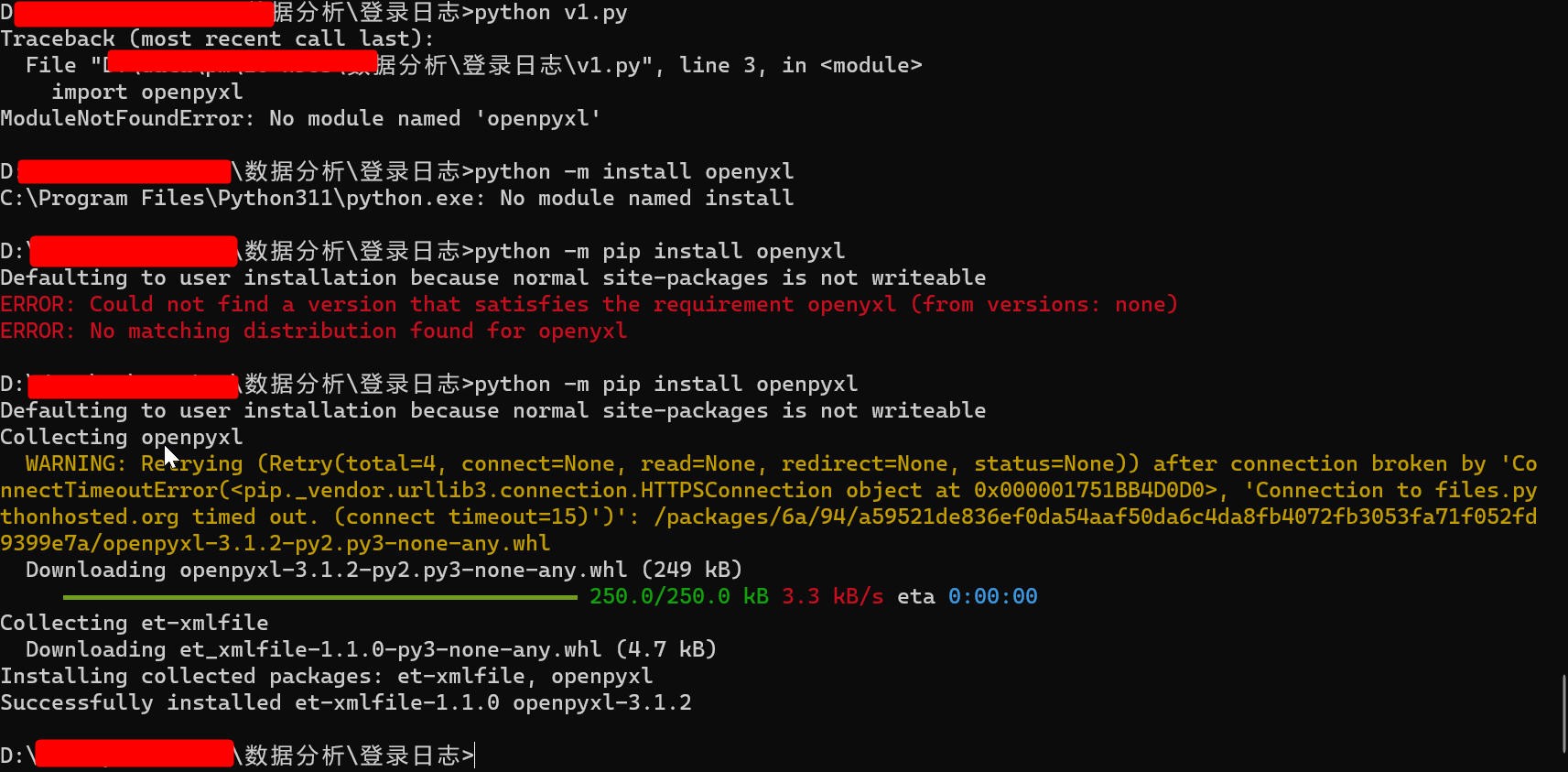
图8 需要安装缺少模块
3.5.2最终训练效果
经过多次优化后的代码如下:
`import os
import glob
import pandas as pd
from tqdm import tqdm
定义函数,用于合并工作簿内容
def merge_workbook_content(workbook_path, output_file):
try:
获取工作簿中所有工作表的名称和数据
xls = pd.ExcelFile(workbook_path)
sheet_names = xls.sheet_names
data_frames = [pd.read_excel(workbook_path, sheet_name=name) for name in sheet_names]
# 删除名为sheet1的工作表
if 'sheet1' in sheet_names:
data_frames.remove(pd.read_excel(workbook_path, sheet_name='sheet1'))
# 合并所有工作表内容
merged_df = pd.concat(data_frames).fillna('')
# 将合并后的内容导出到txt文件
merged_df.to_csv(output_file, sep=',', index=False)
return True
except Exception as e:
print(f"Error occurred when processing {workbook_path}: {e}")
return False
遍历all目录下的所有xlsx文件,并进行处理
for file_path in tqdm(glob.glob(os.path.join('all', '*.xlsx')), desc="Processing files"):
构造输出文件名
output_file = os.path.splitext(file_path)[0] + '_out.txt'
# 调用函数,处理工作簿并保存结果到txt文件
success = merge_workbook_content(file_path, output_file)
if not success:
print(f"Failed to process {file_path}.") `

图9 数据处理完毕
用同样的方法,利用burpsuite入侵模块,批量获取json文件,保存在all目录,需要对all目录下的文件重命名为txt文件,删除头文件中的前几行,具体以实际文件为准,读取所有的json文件,并自动提取表列名,以逗号分隔,保存为指定txt文件。
代码如下:
`import os
import json
#获取指定目录下所有的文件
dir = 'all' #实际过程需要修改all为实际文件夹名称
all_files = [f for f in os.listdir(dir) if os.path.isfile(os.path.join(dir, f))]
for file in all_files:
#将所有扩展名不是.txt的文件改名为同名.txt文件
if not file.endswith('.txt'):
os.rename(os.path.join(dir, file), os.path.join(dir, os.path.splitext(file)[0] + '.txt'))
file = os.path.splitext(file)[0] + '.txt'
#对于每个txt文件,删除前15行的内容并保存到新的txt文件中根据实际情况修改
with open(os.path.join(dir, file), 'r', encoding='utf-8') as txt_file:
content = txt_file.readlines()
deleted_content = '\n'.join(content[:15])
new_content = ''.join(content[15:])
with open(os.path.join(dir, file), 'w', encoding='utf-8') as txt_file:
txt_file.write(new_content)
#将新的txt文件重命名为同名.json文件,并读取其内容
json_file = os.path.splitext(file)[0] + '.json'
os.rename(os.path.join(dir, file), os.path.join(dir, json_file))
with open(os.path.join(dir, json_file), 'r', encoding='utf-8') as j_file:
data = json.load(j_file)
columns = list(data['data']['list'][0].keys())
rows = []
for item in data['data']['list']:
row_values = []
for column in columns:
value = str(item[column]).replace('\n','').replace(',','')
row_values.append(value)
rows.append(','.join(row_values))
#整理json文件中的数据,并按照列名的顺序写入数据文件out.txt中
with open('out.txt', 'a+', encoding='utf-8') as out_file:
if out_file.tell() == 0:
out_file.write(','.join(columns) + '\n')
out_file.write('\n'.join(rows)+'\n')
print("文件{}中的数据已写入out.txt文件中".format(json_file))
`
3.6总结
通过以上的实际训练,笔者基本没有修改过代码,通过语义描述,将功能及需求描述清楚,通过chatgpt进行多次训练,直接解决笔者现实中的一些问题,通过这个代码解决了过去花费1天时间才能处理完的数据,如今只需要十几分钟就轻松解决。通过这个实际案例,可以预见未来会有更多的应用,有了chatgpt确实可以节省一些成本,一些不太复杂的编程工作可以通过chatgpt辅助来解决,当然通过chatgpt也有一些问题,例如训练后的模型结果上传到哪里,训练的数据会不会泄漏等,这些问题有待实际使用中发现和解决。