在老版本的Linux内核中,空指针引用是一种高度可利用的漏洞类型。当内核不受限制的访问用户空间,并且用户空间能够映射0地址时,可以利用空指针引用漏洞达到权限提升。随着SMEP和SMAP的保护机制的引入,以及2.6.23后使用mmap_min_addr防止非特权程序mmap低地址,现在内核版本通常不会将空指针引用视为安全性问题。本文介绍一种空指针引用利用方法,或者说是一种攻击思路,将空指针引用转化为可用于权限提升的UAF利用。
一、内核缓解机制
对于空指针引用的利用,最原始的方式是在用户态mmap一段内存,让0地址开始的内存成为合法地址,然后在这片内存中伪造数据实现攻击。其中要满足的条件就是用户可以随意映射任意地址的内存,并且内核可以直接访问用户映射出来的这片内存。为了缓解此类漏洞对内核产生的影响,Linux先后加入了诸如SMEP、SMAP、mmap_min_addr等等保护机制,下面简要介绍这几种保护机制。
SMEP:Supervisor Mode Execution Prevention,在内核模式下,将用户空间的内存页标记为不可执行。通过CR4寄存器的第20位来启用或禁用。
SMAP:Supervisor Mode Access Prevention,内核模式下,禁止访问用户空间的数据。
mmap_min_addr:在Linux内核版本2.6.23中引入mmap_min_addr了来阻止非特权程序mmap低地址。尽管都是Linux,但不同的架构上此默认值是不同的,默认配置通常x86上是0x10000,mips上是0x4000,arm上是0x1000,可查看/proc/sys/vm/mmap_min_addr来获得当前系统能mmap的最小地址,更改此文件需要特权。
总之,SMEP和SMAP严格区分R0与R3权限,不再有高权限可以访问低权限任意资源的情况了。此外,当内核从进程上下文中发生空指针引用时,它会生成一个oops。oops与panic不同的是,panic会导致内核崩溃,而oops会尝试以最好的结果进行恢复执行而不会崩溃,通常发生oops会直接跳转到类似于do_exit的函数执行,原理与用户态程序中的stack_chk_fail函数原理相似。发生oops时内核会在dmesg中保存日志和崩溃信息上下文,用于描述崩溃时的寄存器及堆栈状态。
二、引用计数管理不当
对于内核oops,虽然保证了内核不会发生崩溃(但大量的oops也有可能导致崩溃),但是有一个副作用就是没办法再进行后续的清理工作。这就意味着,如果发生oops之前某一个变量被上锁,那么他会一直保持锁的状态,因为发生oops会退出当前的操作,无法再执行到之后的函数,任何临时的内存分配、释放,以及引用计数都将受到此影响。
以下是一个关于空指针引用示例,内核版本5.9.16:
static int show_smaps_rollup(struct seq_file *m, void *v)
{
struct proc_maps_private *priv = m->private;
struct mem_size_stats mss;
struct mm_struct *mm;
struct vm_area_struct *vma;
unsigned long last_vma_end = 0;
int ret = 0;
priv->task = get_proc_task(priv->inode); // [1]
if (!priv->task)
return -ESRCH;
mm = priv->mm; // [2]
if (!mm || !mmget_not_zero(mm)) { // [3]
ret = -ESRCH;
goto out_put_task;
}
memset(&mss, 0, sizeof(mss));
ret = mmap_read_lock_killable(mm); // [4]
if (ret)
goto out_put_mm;
hold_task_mempolicy(priv);
for (vma = priv->mm->mmap; vma; vma = vma->vm_next) {
smap_gather_stats(vma, &mss);
last_vma_end = vma->vm_end;
}
show_vma_header_prefix(m, priv->mm->mmap->vm_start,last_vma_end, 0, 0, 0, 0); // [5]
seq_pad(m, ' ');
seq_puts(m, "[rollup]\n");
__show_smap(m, &mss, true);
release_task_mempolicy(priv);
mmap_read_unlock(mm);
out_put_mm:
mmput(mm);
out_put_task:
put_task_struct(priv->task);
priv->task = NULL;
return ret;
}
此函数用于为进程打印一组统计信息。在[1]处获取task引用,在[2]处如果对于没有映射VMA的task,mm->mmap会为空。在[3]位置对mm进行了一次引用,mmget_not_zero会对mm内部引用计数进行操作。在[4]处对mmap上锁,最后在[5]处,如果在[2]处mm->mmap为空,则mmap->vm_start会发生空指针引用导致内核oops。触发这个oops只需要对于没有VMA的任务上读取/proc/[pid]/smaps_rollup来触发:
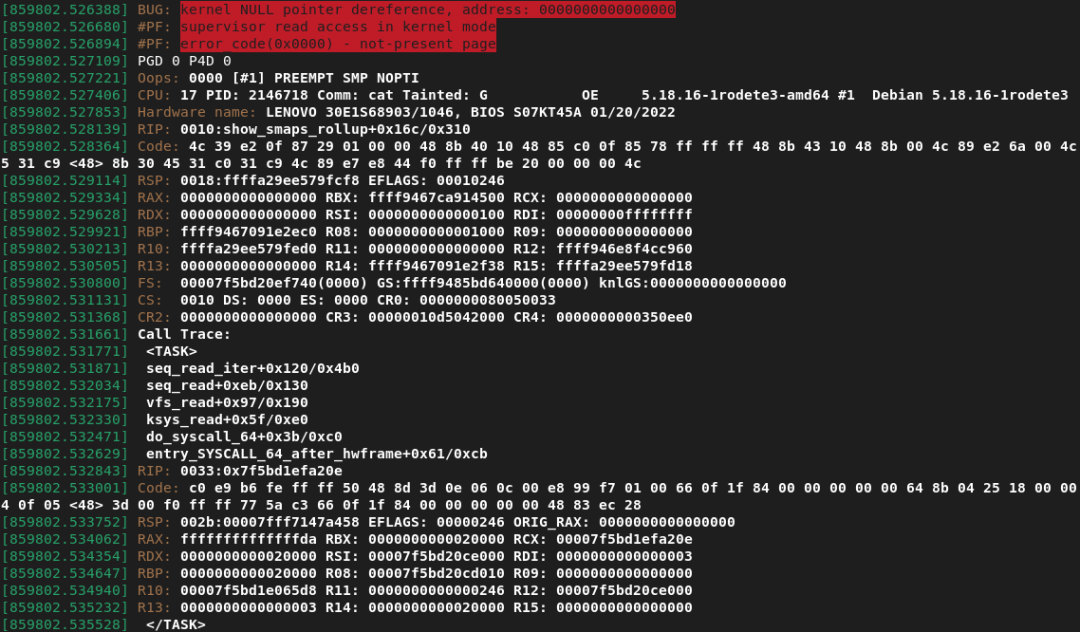
函数调用链如下:
SYSCALL_read
ksys_read
vfs_read
seq_read
seq_read_iter
show_smaps_rollup
通过代码审计后得知,如果在show_smaps_rollup函数中发生oops,将会产生如下影响:
函数开始的priv->task = get_proc_task(priv->inode) 会获取task,函数最后使用put_task_struct(priv->task)取消对task结构体的引用。当发生oops时,由于没有调用到put_task_struct(priv->task),此task的引用将一直存在。
由于mmget_not_zero(mm)会对内部的mm_users引用计数加一,结尾使用mmput(mm)对mm_users引用计数减一。当发生oops时,此引用计数将一直存在。
函数最后的release_task_mempolicy(priv)将不会被执行,也就是说,seq_file->private->task_mempolicy不会被释放。
另外mmap_read_unlock(mm)函数未执行,那么对于文件的读锁将会一直存在。
但并不是每一条都是可利用的,重点关注第二点:对于mm_users引用计数的管理不当。先看看mmget_not_zero函数的定义:
static inline bool mmget_not_zero(struct mm_struct *mm)
{
return atomic_inc_not_zero(&mm->mm_users);
}
mm_struct->mm_users成员是一个atomic_t类型的,而atomic_t定义为一个int类型,此函数中atomic_inc_not_zero是一个宏定义,展开为atomic_add_unless函数,此函数会对引用计数加一。而在发生oops后,mmap_read_unlock函数导致mm->mmap_lock读锁一直存在,因此并不会使引用计数减少,所以理论上可以无限增长这个引用计数,导致atomic_t类型整数溢出。
为了重复增长这个引用计数,我们需要绕过一些障碍:
不能直接调用/proc/self/smaps_rollup的read来重复增长引用计数,因为它本身没有映射虚拟内存,因此我们需要从另一进程中进行读取。
必须每次都重新打开smaps_rollup文件,因为在已经触发 oops 的 smaps_rollup 实例上执行的任何读取都将死锁在本地 seq_file 互斥锁上,该互斥锁将永远锁定。 所以在产生 oops 之后,我们还要通过close销毁struct file,以防止内存耗尽等情况。
如果每次都使用相同pid去访问mm,那么在溢出mm_users之前就会达到task struct的最大引用计数导致失败。因此我们需要创建两个使用相同mm的task,并且在两个task之间做好平衡,保证它们各占mm_users引用计数的一半,我们可以通过clone的CLONE_VM标志位来做到这一点。
必须避免从具有共享文件描述符表的task中打开或读取 smaps_rollup 文件,否则引用计数会在struct file上就出现问题。这比较容易做到,只要不从多线程程序上read就可以达到这一点。
最终的方案如下:
进程A fork 进程B。
进程B使用PTRACE_TRACEME,以便在从munmap函数返回时发生段错误时,它不会退出,而是进入跟踪停止状态。
进程B使用CLONE_VM | CLONE_PTRACE标志来clone一个新的进程C。
进程B使用munmap函数将其整个虚拟内存地址空间解除映射,这也会解除映射进程C的虚拟内存地址空间。换句话说,进程B解除了它自己的虚拟内存地址空间,并且如果它共享了该空间,则会导致进程C中相关的地址空间也被解除映射。
进程A fork新的子进程D和E,它们将分别访问B和C的smaps_rollup文件
D和E打开并读取B和C的smaps_rollup文件,这将导致oops,然后D和E会被kill,而mm_users将在此时增加引用计数。
进程A重复第五、六步操作,重复2^32次,将会使mm_users溢出。
此方案生成232次内核oops并输出到控制台需要两年时间,效率很低,因此需要重新设计策略。我们可以设计为在多个进程中并行运行,从而提高性能,在图形化用户界面的Kali Linux系统中大概需要8天完成。执行完成后,mm_users引用计数将溢出并被设置为零,即使此时该mm仍被多个进程使用并且可以通过proc文件系统引用。换句话说,可以成功地导致内核中的一个关键数据结构出错,并可能导致系统变得不稳定。
三、利用原语
当mm_users引用计数被设置为0之后,再次调用mmget或mmput将会释放整个mm(只需要打开smaps_rollup文件就可以触发),并导致一个UAF。__mmput函数如下:
static inline void __mmput(struct mm_struct *mm)
{
VM_BUG_ON(atomic_read(&mm->mm_users));
uprobe_clear_state(mm);
exit_aio(mm);
ksm_exit(mm);
khugepaged_exit(mm); /* must run before exit_mmap */
exit_mmap(mm);
mm_put_huge_zero_page(mm);
set_mm_exe_file(mm, NULL);
if (!list_empty(&mm->mmlist)) {
spin_lock(&mmlist_lock);
list_del(&mm->mmlist);
spin_unlock(&mmlist_lock);
}
if (mm->binfmt)
module_put(mm->binfmt->module);
mmdrop(mm);
}
但比较不幸的是函数中exit_mmap(mm)中无条件地以写模式获取mmap_lock。由于此mm的mmap_lock被多次永久性地更新为只读状态,任何调用mmput的操作会在exit_mmap中表现为永久性的死锁,自从特定版本之后(具体来说是64591e8605版本),在exit_mmap中会永久性地阻塞任何调用mmput的操作,导致不可解开的死锁。但是好在死锁之前,执行了如下操作:
uprobe_clear_state(mm)
exit_aio(mm)
ksm_exit(mm)
khugepaged_exit(mm)
此外,在多个task同时触发对mm的mmget/mmput操作时,还可以同时调用mmput函数,从而产生条件竞争。在正常执行中过程中,不太可能在同一个mm上触发多个mmput,因为mmput只会在最后的引用计数减少时被调用,而该操作会将引用计数设置为零。然而在引用计数溢出后,对仍被引用的mm执行的所有mmget/mmput操作将触发mmput,这是因为每个通过mmput将引用计数减少到零的操作,都认为自己独自负责释放相关联的mm。条件竞争模型如下图:
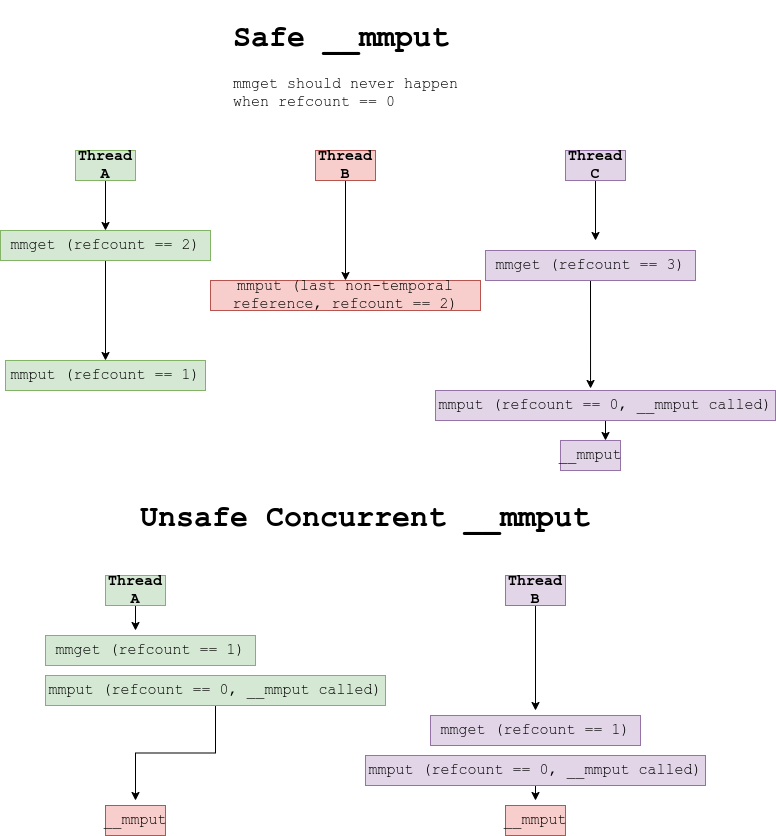
这种存在条件竞争的__mmput函数也会影响到它的被调用者。exit_aio函数就是一个很好的利用原语:
void exit_aio(struct mm_struct *mm)
{
struct kioctx_table *table = rcu_dereference_raw(mm->ioctx_table);
struct ctx_rq_wait wait;
int i, skipped;
if (!table)
return;
atomic_set(&wait.count, table->nr);
init_completion(&wait.comp);
skipped = 0;
for (i = 0; i < table->nr; ++i) {
struct kioctx ctx =
rcu_dereference_protected(table->table, true);
if (!ctx) {
skipped++;
continue;
}
ctx->mmap_size = 0;
kill_ioctx(mm, ctx, &wait);
}
if (!atomic_sub_and_test(skipped, &wait.count)) {
/ Wait until all IO for the context are done. */
wait_for_completion(&wait.comp);
}
RCU_INIT_POINTER(mm->ioctx_table, NULL);
kfree(table);
}
在exit_aio函数中,虽然kill_ioctx函数可以防止并发导致内存损坏,但是exit_aio函数本身并不保证能防止这种情况。因此在同一个mm结构上调用两个并发的exit_aio函数可能会导致对mm->ioctx_table对象进行两次释放,在函数开头获取该对象,然后在函数末尾释放该对象。我们可以通过创建许多aio上下文,以减慢exit_aio的内部上下文释放循环,扩大此竞争时间窗口,提高成功率。成功的利用将触发以下内核BUG,表明已发生double free:
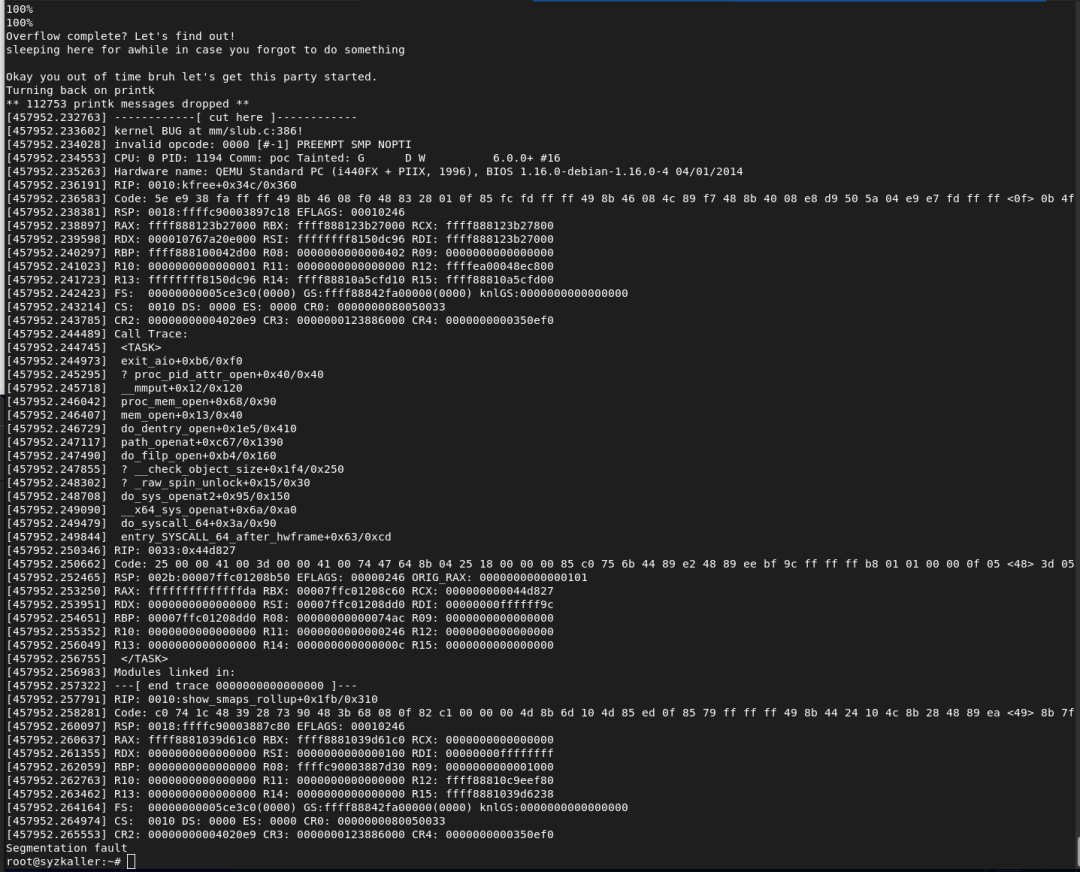
需要注意的是,当后续尝试获取mmap写锁定的进程,再次进入到__mmput中时,会至少有两个永久性死锁进程,因为此时已经进入了竞争状态。但是从利用的角度来看这无关紧要,因为在死锁发生之前,内存损坏原语就已经发生了。而可利用的原语发生在mm->ioctx_table对象的两个释放之间,后续可以利用这个double free构造UAF。从理论上来说是可行的,但实现起来由于多种因素,编写出POC并不是那么容易。
总结
对于此漏洞已于2022年10月被修复。总的来说,此漏洞条件苛刻,利用稍微困难,但本文主要目的还是在于介绍如何将看似不可利用的空指针引用,转化为一个可用于提权的UAF利用,也算是了解了一个新的攻击手法。在以后遇到此类的空指针引用也不应该放过,深挖其中的利用原语,说不定会有意外的收获。
Reference
https://googleprojectzero.blogspot.com/2023/01/exploiting-null-dereferences-in-linux.html