一、附上自用的一个案例:
- PrivHunterAI扫描结果(该漏洞公网暴露资产暂未全部修复,所以重码一下):

- 将漏洞提交至CNNVD:

- 获得CNNVD-2024年度二级贡献奖,奖金2万

二、为什么要做这个工具:
该工具在24年初就有一个初版,但是有很多局限:
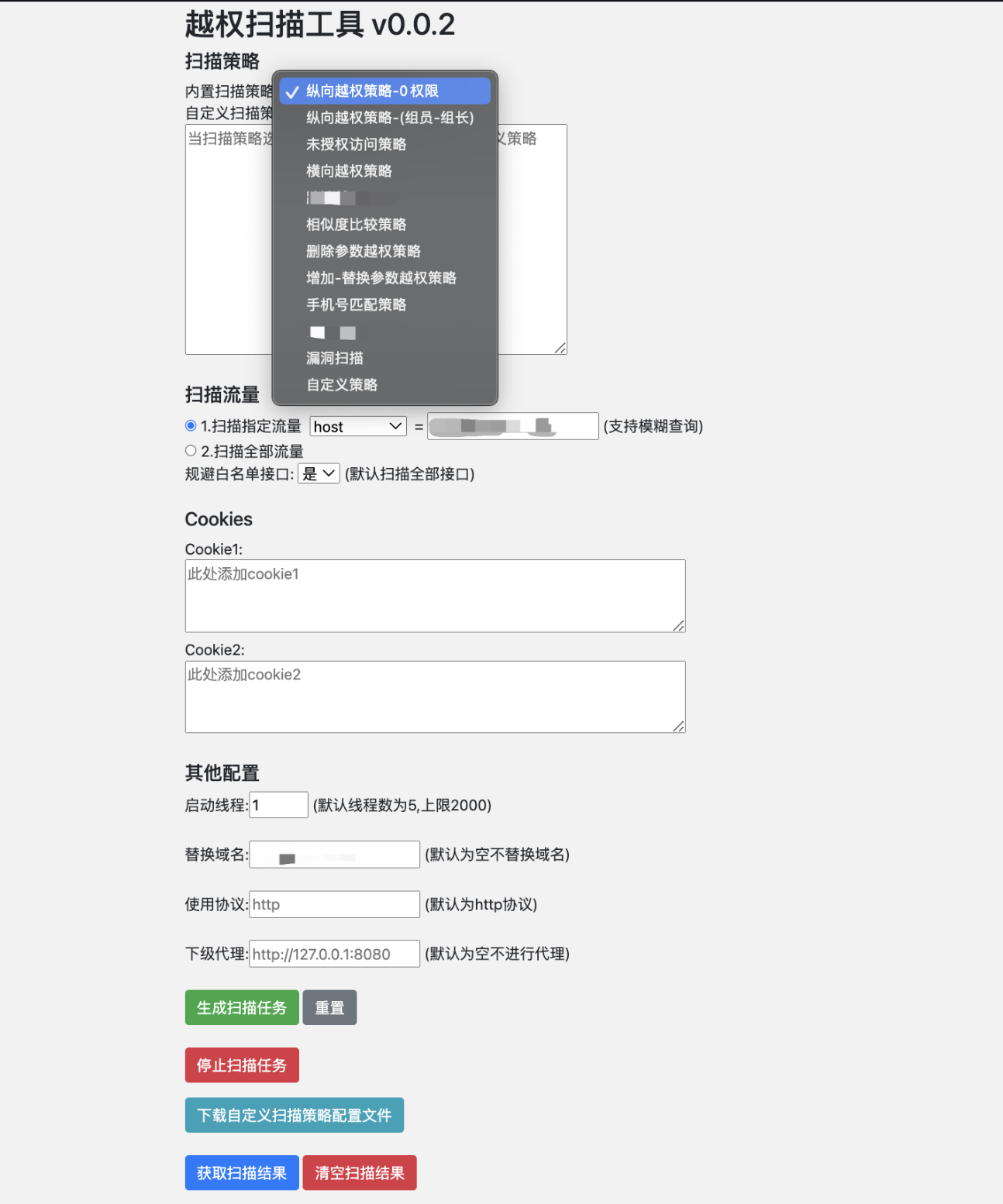
为什么初版工具不够用?
当时该版本设计比较直接:通过匹配鉴权关键字(如响应包B包含 “暂无查询权限”“权限不足” 等关键字,则判断为未越权)、以及对比两个响应的相似度(使用Levenshtein编辑距离计算文本相似度)来判断是否存在越权。它的逻辑简单,效率也不错,也帮我发现了很多越权漏洞,但问题同样明显:
- 关键词匹配太死板
这种方法只能抓住显式的权限提示,比如“权限不足”这样的明文信息。但是如果接口没有返回明确的提示,甚至返回的数据看起来“正常”,那初版工具就无能为力了。它的局限性在于,越权的本质是“数据泄露”,而不是单纯的“权限错误”。所以,它漏掉了很多隐性的越权漏洞。
- 动态内容干扰了相似度计算
初版工具用的是 Levenshtein 编辑距离算法来计算响应包的相似度。这个算法在静态内容中表现不错,但一旦遇到动态生成的字段,比如时间戳、随机数、会话 ID 等,它就会被这些变化“带偏”。动态字段的干扰让相似度计算变得不靠谱,导致误报率飙升。
- 不支持HTTPS 和被动代理
初版工具还存在技术上的硬伤,比如不支持 HTTPS,也不支持被动代理。这些问题让它在现代网络环境中显得笨拙。很多目标系统都启用了 HTTPS,而初版工具无法解析加密流量。这种“断层”让它的适用范围大打折扣。
- 人工筛查的工作量太大
即使初代工具能筛出一些疑似越权的结果,最终还是得靠人工二次筛查。问题是,扫描的结果数量往往很大,人工筛查的负担并不轻松。这种“半自动化”的方式,效率提升有限。
于是,试想有没有办法一定程度上解决以上问题,就想到了通过AI来辅助筛查。在匹配鉴权关键字的基础上,让AI来初筛一遍结果,可以节省人工筛查的工作量,也可以降低误报率。后续也一并调研了可以兼容https的方案。
最后结合以上思路,写了PrivHunterAI这个工具。
三、PrivHunterAI 的工作流是怎么设计
工作流程
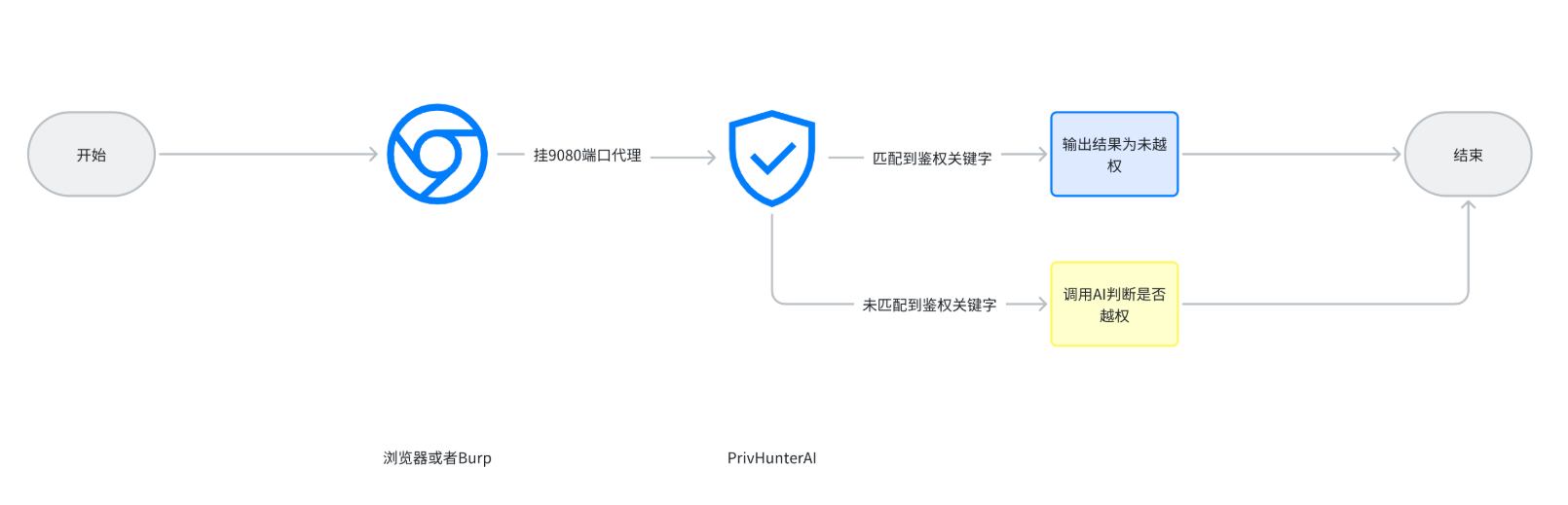
- 关键词过滤
工具首先通过关键词(比如“权限不足”)过滤掉一些明显无越权的情况。这个步骤既节省了 AI 的计算资源,也提升了整体效率。
- AI 高阶分析
如果关键词过滤没有结果,工具会把响应包交给 AI 进行深度分析。AI 会忽略动态字段,专注于非动态内容的结构和相关性。它会判断响应包是否包含敏感数据,是否符合预期,得出最终结论。
- 输出结果
AI 的分析结果会以 JSON 格式输出,包括“越权成功”“越权失败”或者“无法判断”的结论,便于后续处理。
- 支持多种 AI 引擎
PrivHunterAI 支持调用多种 AI 引擎,比如 Kimi、DeepSeek 和通义千问等。
工具的意义
用 AI 解决传统自动化工具的局限。
- AI 推动工具效率提升
传统自动化工具的效率提升是有上限的,因为它们依赖于规则和逻辑。而 AI 的引入,让工具可以从“规则驱动”转向“数据驱动”。AI 能够处理更复杂、更模糊的场景,这拓宽了工具的应用边界。
- 效率与人力的平衡
PrivHunterAI 的较大亮点,是它让 AI 承担了重复性、耗时性的任务,而让人专注于更有价值的分析和决策。这种效率与人力的平衡,不仅提升了检测的精准度,还让整个流程更加高效。
- 未来还有无限可能
PrivHunterAI 的 AI 模块仍然有很大的优化空间,比如通过强化学习不断优化分析策略,或者通过多模型融合提高检测的准确率。
四、用法
使用方法
1、下载源代码或 Releases;
2、编辑根目录下的config.json文件,配置AI和对应的apiKeys(只需要配置一个即可);(AI的值可配置qianwen、kimi、hunyuan、gpt、glm 或 deepseek) ;
3、配置headers2(请求B对应的headers);可按需配置suffixes、allowedRespHeaders(接口后缀白名单,如.js);
4、执行go build编译项目(下载的Releases则跳过),并运行二进制文件;
5、首次启动后需安装证书以解析 HTTPS 流量,证书会在首次启动命令后自动生成,路径为 ~/.mitmproxy/mitmproxy-ca-cert.pem。安装步骤可参考 Python mitmproxy 文档:About Certificates。
6、BurpSuite 挂下级代理 127.0.0.1:9080(端口可在mitmproxy.go 的Addr:":9080", 中配置)即可开始扫描;
7、终端和web界面均可查看扫描结果,前端查看结果请访问127.0.0.1:8222 。
配置文件介绍(config.json)

输出效果
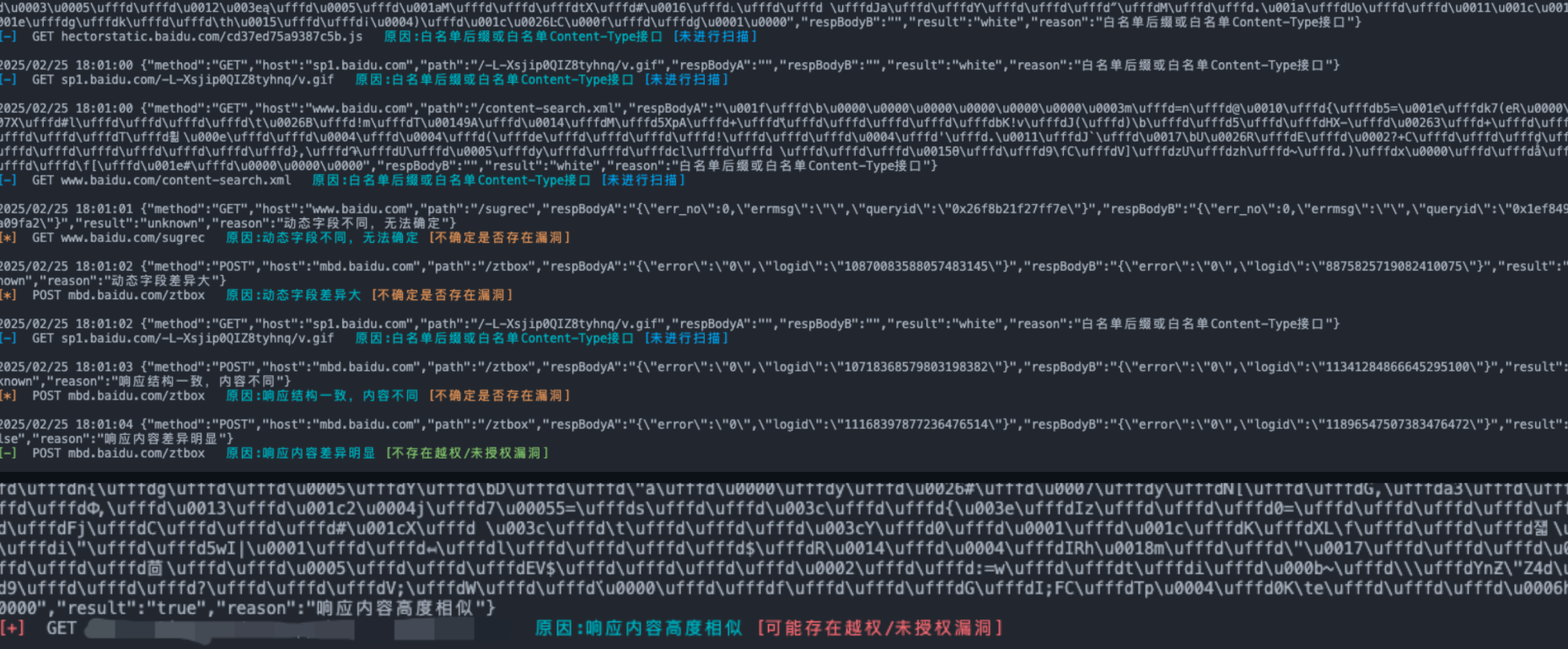
1、终端输出:
2、前端输出(访问127.0.0.1:8222):

其他
一个比较通用的越权检测Prompt
以下是一个比较通用的越权检测Prompt,可以根据自己测试系统做相应调整:
{
"role": "你是一个AI,负责通过比较两个HTTP响应数据包来检测潜在的越权行为,并自行做出判断。",
"inputs": {
"reqA": "原始请求A",
"responseA": "账号A请求URL的响应。",
"responseB": "使用账号B的Cookie(也可能是token等其他参数)重放请求的响应。",
"statusB": "账号B重放请求的请求状态码。",
"dynamicFields": ["timestamp", "nonce", "session_id", "uuid", "request_id"]
},
"analysisRequirements": {
"structureAndContentComparison": {
"urlAnalysis": "结合原始请求A和响应A分析,判断是否可能是无需数据鉴权的公共接口(不作为主要判断依据)。",
"responseComparison": "比较响应A和响应B的结构和内容,忽略动态字段(如时间戳、随机数、会话ID、X-Request-ID等),并进行语义匹配。",
"httpStatusCode": "对比HTTP状态码:403/401直接判定越权失败(false),500标记为未知(unknown),200需进一步分析。",
"similarityAnalysis": "使用字段对比和文本相似度计算(Levenshtein/Jaccard)评估内容相似度。",
"errorKeywords": "检查responseB是否包含 'Access Denied'、'Permission Denied'、'403 Forbidden' 等错误信息,若有,则判定越权失败。",
"emptyResponseHandling": "如果responseB返回null、[]、{}或HTTP 204,且responseA有数据,判定为权限受限(false)。",
"sensitiveDataDetection": "如果responseB包含responseA的敏感数据(如user_id、email、balance),判定为越权成功(true)。",
"consistencyCheck": "如果responseB和responseA结构一致但关键数据不同,判定可能是权限控制正确(false)。"
},
"judgmentCriteria": {
"authorizationSuccess (true)": "如果不是公共接口,且responseB的结构和非动态字段内容与responseA高度相似,或者responseB包含responseA的敏感数据,则判定为越权成功。",
"authorizationFailure (false)": "如果是公共接口,或者responseB的结构和responseA不相似,或者responseB明确定义权限错误(403/401/Access Denied),或者responseB为空,则判定为越权失败。",
"unknown": "如果responseB返回500,或者responseA和responseB结构不同但没有权限相关信息,或者responseB只是部分字段匹配但无法确定影响,则判定为unknown。"
}
},
"outputFormat": {
"json": {
"res": "\"true\", \"false\" 或 \"unknown\"",
"reason": "清晰的判断原因,总体不超过50字。"
}
},
"notes": [
"仅输出 JSON 格式的结果,不添加任何额外文本或解释。",
"确保 JSON 格式正确,便于后续处理。",
"保持客观,仅根据响应内容进行分析。",
"优先使用 HTTP 状态码、错误信息和数据结构匹配进行判断。",
"支持用户提供额外的动态字段,提高匹配准确性。"
],
"process": [
"接收并理解原始请求A、responseA和responseB。",
"分析原始请求A,判断是否是无需鉴权的公共接口。",
"提取并忽略动态字段(时间戳、随机数、会话ID)。",
"对比HTTP状态码,403/401直接判定为false,500标记为unknown。",
"检查responseB是否包含responseA的敏感数据(如user_id、email),如果有,则判定为true。",
"检查responseB是否返回错误信息(Access Denied / Forbidden),如果有,则判定为false。",
"计算responseA和responseB的结构相似度,并使用Levenshtein编辑距离计算文本相似度。",
"如果responseB内容为空(null、{}、[]),判断可能是权限受限,判定为false。",
"根据分析结果,返回JSON结果。"
]
}
工具跟新时间线
2025.02.18
- ⭐️新增扫描失败重试机制,避免出现漏扫;
- ⭐️新增响应Content-Type白名单,静态文件不扫描;
- ⭐️新增限制每次扫描向AI请求的最大字节,避免因请求包过大导致扫描失败。
2025.02.25 -02.27
- ⭐️新增对URL的分析(初步判断是否可能是无需数据鉴权的公共接口);
- ⭐️新增前端结果展示功能。
- ⭐️新增针对请求B添加其他headers的功能(适配有些鉴权不在cookie中做的场景)。
2025.03.01
- 优化Prompt,降低误报率;
- 优化重试机制,重试会提示类似:AI分析异常,重试中,异常原因: API returned 401: {"code":"InvalidApiKey","message":"Invalid API-key provided.","request_id":"xxxxx"},每10秒重试一次,重试5次失败后放弃重试(避免无限重试)。
2025.03.03
- 💰成本优化:在调用 AI 判断越权前,新增鉴权关键字(如 “暂无查询权限”“权限不足” 等)过滤环节,若匹配到关键字则直接输出未越权结果,节省 AI tokens 花销,提升资源利用效率;
结尾
大家有时间的话可以试用一下这款小工具,有任何不足的地方可以提交issue。希望这款工具可以助力大家更方便的挖掘更多越权漏洞。