- 已编辑

这应该是在爬虫或漏洞扫描器开发时是个很重要的功能,懂得都懂,哈哈哈。
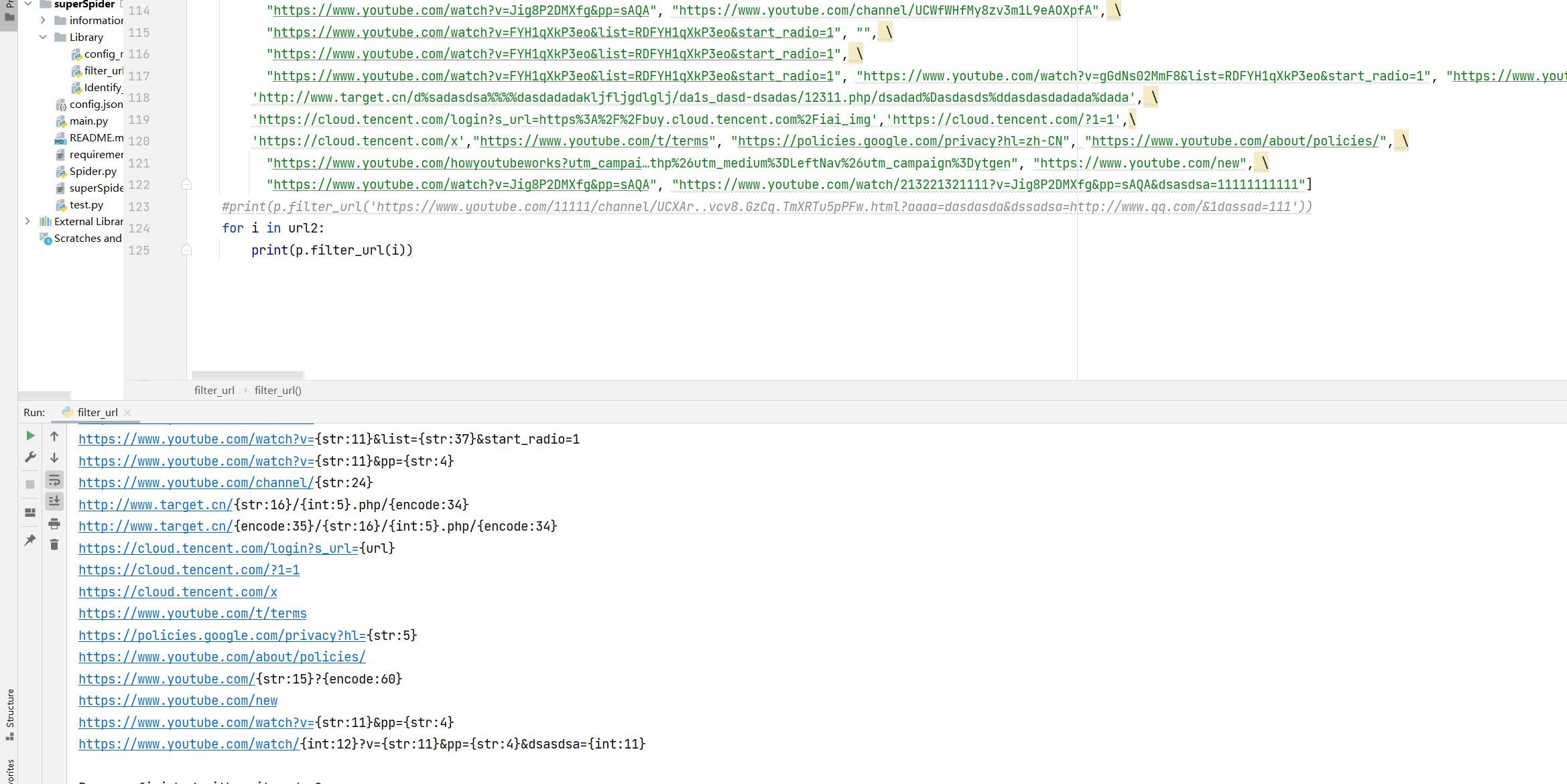
代码逻辑如下:
https://www.youtube.com/11111/channel/UCXAr..vcv8.GzCq.TmXRTu5pPFw.html?aaaa=dasdasda&dssadsa=http://www.qq.com/&1dassad=111
https://www.youtube.com/{int:5}/channel/{str:28}.html?aaaa={str:8}&dssadsa={url}&1dassad={int:3}相对应的把URL的目录名和参数值泛化掉, 泛化逻辑是: 字符串、数字、英文单词、和url。
大概能搞定%90以上的重复率去重问题,也竟可能的保留真实有效的页面。
代码如下:
"""
Created on Jul 10, 2019
@Author: guimaizi
@File: filter_url.py
@Software: PyCharm
"""
import urllib.parse,enchant,re
from urllib import parse
class filter_url:
def __init__(self):
'''处理url去重相关'''
self.list_url_static=[]
def filter_url(self,url):
#print(url)
url_process=urllib.parse.urlparse(url)
if url_process.query!='':
return self.static_filter(urllib.parse.urlparse(self.params_filter(url_process)))
elif url_process.path=='' or url_process.path=='/':
return url
elif url_process.query=='':
return self.static_filter(url_process)
def params_filter(self,url):
#url参数处理
try:
liststr = []
for i in url.query.split('&'):
para = i.split('=')
length_int = len(para[1])
if self.judgetype(para[1]) == 'int' and len(para[1])>1:
para[1] = '{int:%s}' % length_int
elif self.judgetype(para[1]) == 'str' and len(para[1])>1:
para[1] = '{str:%s}' % length_int
elif self.judgetype(para[1]) == 'encode' and len(para[1])>1:
para[1] = '{encode:%s}' % length_int
elif parse.unquote(para[1]).startswith('http://') or parse.unquote(para[1]).startswith('https://'):
para[1] = '{url}'
else:
para[1] = para[1]
para = '='.join(para)
liststr.append(para)
url_paras='&'.join(liststr)
return url.scheme + '://' + url.netloc + url.path + '?' + url_paras
except:
length_int = len(url.query)
url_paras = '{'+self.judgetype(url.query) + ':%s}' % length_int
return url.scheme + '://' + url.netloc + url.path + '?' + url_paras
def static_filter(self,url):
# 伪静态与url路径处理
#print(url)
urls = url.path
folder_name_list=[]
d_enchant = enchant.Dict("en_US")
for folder_name in urls.split('/'):
if self.judgetype(folder_name.strip())=='int':
folder_name_list.append('{%s:%s}'%(self.judgetype(folder_name.strip()),str(len(folder_name.strip()))))
elif len(folder_name.strip())>1 and d_enchant.check(folder_name.strip())==False:
name = folder_name.split('.')
if len(name) > 1 and name[-1].lower() in ['htm', 'html', 'xhtml', 'shtml', 'php', 'jsp', 'jspx', 'do','action', 'aspx', 'asp', 'py']:
folder_name_list.append('{%s:%s}.%s' % (self.judgetype('.'.join(name[0:-1]).strip()), str(len('.'.join(name[0:-1]).strip())),name[-1]))
else:
folder_name_list.append('{%s:%s}'%(self.judgetype(folder_name.strip()),str(len(folder_name.strip()))))
else:folder_name_list.append(folder_name.strip())
url_path = "/".join(folder_name_list)
if url.query != '':
return url.scheme + '://' + url.netloc + url_path + '?' + url.query
else:
return url.scheme + '://' + url.netloc + url_path
def judgetype(self, strs):
try:
if parse.unquote(strs).startswith('http://') or parse.unquote(strs).startswith('https://'):
return 'url'
elif strs.count('%')>2 and len(strs)>22:
return 'encode'
elif int(strs):return 'int'
except:
return 'str'
if __name__ == '__main__':
urls_target = ['http://www.target.cn/zxft/20483.htm?dsdsa','http://www.target.cn/zxft.php', \
'http://www.target.cn/zxft/20483.htm','http://www.target.cn/zxft/20483.htm?dsdsa=dsadsa&dada=1', \
'http://www.target.cn/zxft/31231.htm','http://www.target.cn/zxft/31231', \
'http://www.target.cn/','http://www.target.cn/zxft/20483.htm?dsdsa=ds1adsa&dada=231231', \
'http://www.target.cn/dsadsa/','http://www.target.cn/2131','http://www.target.cn/user', \
'http://www.target.cn/da1s_dasd/','http://www.target.cn/das_dasd?das=121','http://www.target.cn/index.php/thanks', \
'http://www.target.cn/?a=dasd','http://www.target.cn/da1s_dasd-dsadas/12311.php/','http://www.target.cn/?a=dasd#dasda', \
'http://www.target.cn/da1s_dasd-dsadas/12311.php/aa?das=213&dasda=12321&dsada=dada%%',
'http://www.target.cn/da1s_dasd-dsadas/12311.php/aa?das=213&dasda=12321&dsada=dada%%dasdasdasda%fdfsd', \
'http://www.target.cn/da1s_dasd-dsadas/12311.php/dsadad%Dasdasds%ddasdasdadada%dada', \
'http://www.target.cn/d%sadasdsa%%%%dasdadadakljfljgdlglj/da1s_dasd-dsadas/12311.php/dsadad%Dasdasds%ddasdasdadada%dada', \
'https://cloud.tencent.com/login?s_url=https%3A%2F%2Fbuy.cloud.tencent.com%2Fiai_img','https://cloud.tencent.com/?1=1',\
'https://cloud.tencent.com/x']
p = filter_url()
#for i in urls_target:
# print(p.filter_url(i))
url='http://www.target.cn/d%sadasdsa%%%%dasdadadakljfljgdlglj/a/da1s_dasd-dsadas/12311.php/dsadad%Dasdasds%ddasdasdadada%dada/dog/.../aaa/class-response?aaaa=111'
url1='http://www.target.cn/aaaaaaaa?xssssss'
url2=["https://www.youtube.com/", "https://www.youtube.com/", "https://www.youtube.com/", "https://www.youtube.com/feed/explore", \
"https://www.youtube.com/feed/subscriptions", "https://www.youtube.com/feed/library", "https://www.youtube.com/feed/history",\
"https://studio.youtube.com/channel/UCawMf0xhD9UPcDhPWPUKuKA/videos", "https://www.youtube.com/playlist?list=WL",\
"https://www.youtube.com/playlist?list=LL", "", "", "https://www.youtube.com/channel/UC_k-yz7etVINn3ZhHjvVQ_A",\
"https://www.youtube.com/channel/UC02fgHaylaYErlJxnuGMPaA", "https://www.youtube.com/channel/UCt5zpwa264A0B-gaYtv1IpA",\
"https://www.youtube.com/channel/UCPZZqzNXp041mw-wZyvqMLA", "https://www.youtube.com/channel/UCnAsZ46UTeFEgwOEwMezngQ",\
"https://www.youtube.com/channel/UCfIbForcbE83cxm8MScOTlQ", "https://www.youtube.com/channel/UC5If9nG2OCtc3j55PtPv5iw",\
"", "", "https://www.youtube.com/premium", "https://www.youtube.com/feed/storefront?bp=ogUCKAI%3D", "https://www.youtube.com/gaming",\
"https://www.youtube.com/channel/UC4R8DWoMoI7CAwX8_LjQHig", "https://www.youtube.com/channel/UCrpQ4p1Ql_hG8rKXIKM1MOQ",\
"https://www.youtube.com/channel/UCtFRv9O2AHqOZjjynzrv-xg", "https://www.youtube.com/channel/UCEgdi0XIXXZ-qJOFPf4JSKw",\
"https://www.youtube.com/account", "https://www.youtube.com/reporthistory", "", "", "https://www.youtube.com/about/",\
"https://www.youtube.com/about/press/", "https://www.youtube.com/about/copyright/", "https://www.youtube.com/t/contact_us/",\
"https://www.youtube.com/creators/", "https://www.youtube.com/ads/", "https://developers.google.com/youtube",\
"https://www.youtube.com/t/terms", "https://policies.google.com/privacy?hl=zh-CN", "https://www.youtube.com/about/policies/", \
"https://www.youtube.com/howyoutubeworks?utm_campai…thp%26utm_medium%3DLeftNav%26utm_campaign%3Dytgen", "https://www.youtube.com/new", "", "",\
"https://www.youtube.com/watch?v=Jig8P2DMXfg&pp=sAQA", "https://www.youtube.com/channel/UCWfWHfMy8zv3m1L9eAOXpfA",\
"https://www.youtube.com/watch?v=Jig8P2DMXfg&pp=sAQA", "https://www.youtube.com/channel/UCWfWHfMy8zv3m1L9eAOXpfA", \
"https://www.youtube.com/watch?v=FYH1qXkP3eo&list=RDFYH1qXkP3eo&start_radio=1", "", \
"https://www.youtube.com/watch?v=FYH1qXkP3eo&list=RDFYH1qXkP3eo&start_radio=1", \
"https://www.youtube.com/watch?v=FYH1qXkP3eo&list=RDFYH1qXkP3eo&start_radio=1", "https://www.youtube.com/watch?v=gGdNs02MmF8&list=RDFYH1qXkP3eo&start_radio=1", "https://www.youtube.com/watch?v=IRepClFlA9c&pp=sAQA", "https://www.youtube.com/channel/UC9zVS70p4LiTycVIjesLk6w", "https://www.youtube.com/watch?v=IRepClFlA9c&pp=sAQA", "https://www.youtube.com/channel/UC9zVS70p4LiTycVIjesLk6w", "https://www.youtube.com/watch?v=e51JUlvjUEI&list=RDe51JUlvjUEI&start_radio=1", "", "https://www.youtube.com/watch?v=e51JUlvjUEI&list=RDe51JUlvjUEI&start_radio=1", "https://www.youtube.com/watch?v=e51JUlvjUEI&list=RDe51JUlvjUEI&start_radio=1", "https://www.youtube.com/watch?v=NjTT5_RSkw4&list=RDe51JUlvjUEI&start_radio=1", "https://www.youtube.com/watch?v=Pyntgx9rjhU&list=RDPyntgx9rjhU&start_radio=1", "", "https://www.youtube.com/watch?v=Pyntgx9rjhU&list=RDPyntgx9rjhU&start_radio=1", "https://www.youtube.com/watch?v=Pyntgx9rjhU&list=RDPyntgx9rjhU&start_radio=1", "https://www.youtube.com/watch?v=RkQy3NlG1eo&list=RDPyntgx9rjhU&start_radio=1", "https://www.youtube.com/watch?v=DVrG2xUHTuA&list=RDDVrG2xUHTuA&start_radio=1", "", "https://www.youtube.com/watch?v=DVrG2xUHTuA&list=RDDVrG2xUHTuA&start_radio=1", "https://www.youtube.com/watch?v=DVrG2xUHTuA&list=RDDVrG2xUHTuA&start_radio=1", "https://www.youtube.com/watch?v=aHNsuYHlMQM&list=RDDVrG2xUHTuA&start_radio=1", "https://www.youtube.com/watch?v=kqhXK51AVec&list=RDkqhXK51AVec&start_radio=1", "", "https://www.youtube.com/watch?v=kqhXK51AVec&list=RDkqhXK51AVec&start_radio=1", "https://www.youtube.com/watch?v=kqhXK51AVec&list=RDkqhXK51AVec&start_radio=1", "https://www.youtube.com/watch?v=KZbswFDOOsY&list=RDkqhXK51AVec&start_radio=1", "https://www.youtube.com/watch?v=5__g-d6tmeQ&pp=sAQA", "https://www.youtube.com/channel/UC_k-yz7etVINn3ZhHjvVQ_A", "https://www.youtube.com/watch?v=5__g-d6tmeQ&pp=sAQA", "https://www.youtube.com/channel/UC_k-yz7etVINn3ZhHjvVQ_A", "https://www.youtube.com/watch?v=dHMCpR4VFT8&pp=sAQA", "https://www.youtube.com/c/kankanews", "https://www.youtube.com/watch?v=dHMCpR4VFT8&pp=sAQA", "https://www.youtube.com/c/kankanews", "https://www.youtube.com/watch?v=VhCRokYVF1I&list=R…Q1dJ7wXfLlqCjwV0xfSNbAVMVhCRokYVF1I&start_radio=1", "", "https://www.youtube.com/watch?v=VhCRokYVF1I&list=R…Q1dJ7wXfLlqCjwV0xfSNbAVMVhCRokYVF1I&start_radio=1", "https://www.youtube.com/watch?v=VhCRokYVF1I&list=R…Q1dJ7wXfLlqCjwV0xfSNbAVMVhCRokYVF1I&start_radio=1", "https://www.youtube.com/watch?v=Hn8yhgxpzS4&list=R…Q1dJ7wXfLlqCjwV0xfSNbAVMVhCRokYVF1I&start_radio=1", "https://www.youtube.com/watch?v=wiEPOLB5t-8&pp=sAQA", "https://www.youtube.com/channel/UCXArvcv8GzCqTmXRTu5pPFw",'http://www.target.cn/da1s_dasd-dsadas/12311.php/dsadad%Dasdasds%ddasdasdadada%dada', \
'http://www.target.cn/d%sadasdsa%%%%dasdadadakljfljgdlglj/da1s_dasd-dsadas/12311.php/dsadad%Dasdasds%ddasdasdadada%dada', \
'https://cloud.tencent.com/login?s_url=https%3A%2F%2Fbuy.cloud.tencent.com%2Fiai_img','https://cloud.tencent.com/?1=1',\
'https://cloud.tencent.com/x',"https://www.youtube.com/t/terms", "https://policies.google.com/privacy?hl=zh-CN", "https://www.youtube.com/about/policies/", \
"https://www.youtube.com/howyoutubeworks?utm_campai…thp%26utm_medium%3DLeftNav%26utm_campaign%3Dytgen", "https://www.youtube.com/new", \
"https://www.youtube.com/watch?v=Jig8P2DMXfg&pp=sAQA", "https://www.youtube.com/watch/213221321111?v=Jig8P2DMXfg&pp=sAQA&dsasdsa=11111111111"]
#print(p.filter_url('https://www.youtube.com/11111/channel/UCXAr..vcv8.GzCq.TmXRTu5pPFw.html?aaaa=dasdasda&dssadsa=http://www.qq.com/&1dassad=111'))
for i in url2:
print(p.filter_url(i))执行结果: