目录:
1.前言
2.项目结构
2.1 简单首页爬取
2.2 selenium环境配置
3.爬虫思路分析
3.1 爱站子域名爬取
3.2 站长之家子域名爬取
4.最终实现效果
1.前言
对于渗透来说,前期的信息搜集至关重要。信息搜集要快准狠。国内的两个SEO搜索引擎也帮得上忙。对于一个主站,如果无法突破,我们通常会从旁站入手。这时子域名的搜集就很关键。子域名搜集有很多工具,但几乎都是基于字典爆破的方式。如:子域名挖掘机(Layer)、ksubdomain、subDomainsBrute、dnscan等均是基于被动搜集的,并且爆破是需要时间的,字典越大,爆破时间越长。听了上一期的大壮师傅讲的信息收集之后,觉得这个工具也许可以排上用场。
并且,在SEO搜索引擎获取的子域名是按权重排序的。现在各大SRC平台都要求站点的权重达到多少才有奖励,这对挖洞白帽来说也很nice。
2.项目结构
DomainSpiderSE/
├── aiStand_domainCrawl.py #爱站子域名爬虫
├── spiderSE.py #运行调用脚本
└── webMaster_domainCrawl.py #站长之家子域名爬虫
[项目地址:](https://github.com/ltfafei/DomainSpiderSE)
https://github.com/ltfafei/DomainSpiderSE
缺点:
(1)爱站网只能显示权重排行前50个子域名;
(2)站长之家只能显示权重排行前100个子域名,想要获取更多需要开会员。
2.1 简单首页爬取
某个目标首页的子域名获取主要使用了requests和bs4模块。
#!/usr/bin/python
# Env: python3
# Author: afei00123
# -*- coding: utf8 -*-
import requests, urllib3
from bs4 import BeautifulSoup
def aiStand_Crawl(url):
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
urls = f"https://rank.aizhan.com/{url}/"
repon = requests.get(url=urls, timeout=3).text
soup1 = BeautifulSoup(repon, "html.parser")
soup1_data = str(soup1.find_all("td", class_="site"))
soup2 = BeautifulSoup(soup1_data, "html.parser")
soup2_data = soup2.find_all("a")
for i in range(len(soup2_data)):
res = str(soup2_data[i].contents).split("'")[1]
print(res)
aiStand_Crawl("xxx.edu.cn")
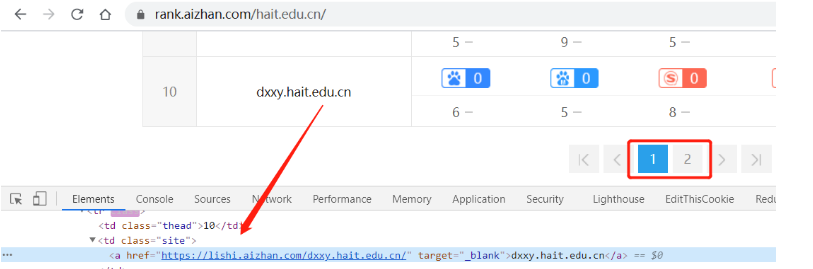
__
以上只能爬取当前页面子域名,其他页面子域名的爬取需要用到selenium模块进行翻页爬取。
2.2 selenium环境配置
(1)根据Chrome版本下载chromedriver。国内chromedriver镜像下载地址:http://npm.taobao.org/mirrors/chromedriver/
(2)下载zip后解压,将chromedriver.exe文件复制到Chrome的Google/Chrome/Application目录和Python安装目录下。
参考文章:
初始化driver:
def __init__(self):
options = Options()
options.add_argument("--headless")
self.driver = webdriver.Chrome(options=options)
3.爬虫思路分析
3.1 爱站子域名爬取
定位翻页标签:

#翻页爬取到倒数第二页
while True:
next_pg = self.driver.find_element_by_id("ajaxNext")
next_page_num1 = next_pg.get_attribute("data-page")
next_pg.click()
time.sleep(1)
next_pg = self.driver.find_element_by_id("ajaxNext")
next_page_num2 = next_pg.get_attribute("data-page")
if next_page_num1 < next_page_num2:
print("\033[31m [+] 正在翻页爬取第二页至倒数第二页子域名...")
self.get_url(files)
else:
break
爬取URL:
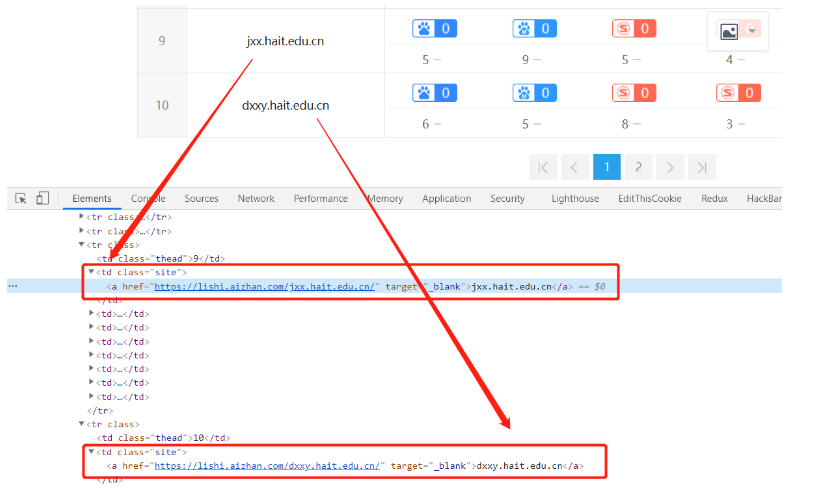
def get_url(self, files):
tbody = self.driver.find_elements_by_xpath("//td[@class='site']/a")
for a in list(tbody):
url = a.text
with open(files, "a+") as fw:
fw.write(url + "\n")
3.2 站长之家子域名爬取
翻页标签获取:
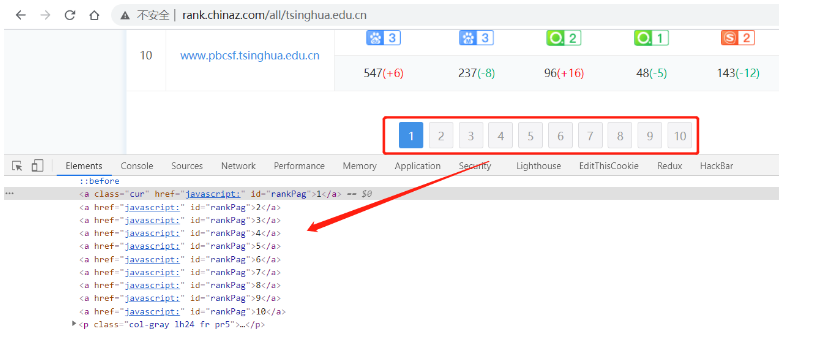
page_list = self.driver.find_elements_by_xpath("//div[@id='pagelist']/a")
翻页并获取URL:

print("\n \033[31m[+] 正在爬取所有页面子域名...")
for a in page_list:
#不直接使用a.click(),避免元素定位相互覆盖
self.driver.execute_script("arguments[0].click()", a)
time.sleep(2)
url_list = self.driver.find_elements_by_xpath("//td[@class='bor-r1s subdomain']/a")
for a in url_list:
urlstr = a.text
with open(files, "a") as fw:
if urlstr.split(): #去除空行
fw.write(urlstr+ "\n")
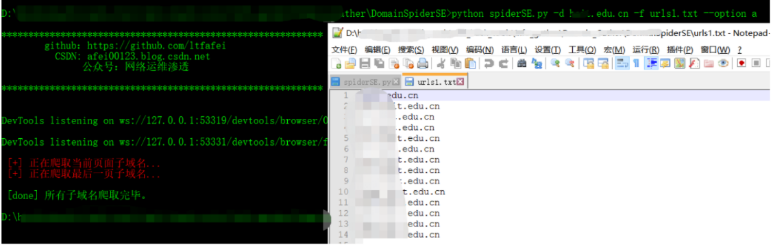
4.最终实现效果
python spiderSE.py -d xxx.cn -f urls.txt
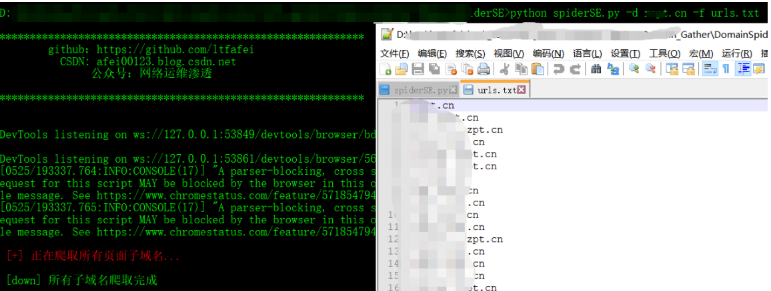
python spiderSE.py -d xxx.edu.cn -f urls1.txt --option a_
工具拿走不谢!创作不易,别忘了文章底下点个赞👍再走。github fork时别忘了赞一个,爱你呦!
火线的编辑器有点太...,确实不好使,希望能改进。